
How Drasi Leverages AI Synthetic Users to Solve the Documentation Drift Crisis in Open Source Development
The efficacy of an early-stage open-source project is often determined within the first few minutes of a developer’s interaction, specifically during the execution of the "Getting Started" guide. For projects in the Cloud Native Computing Foundation (CNCF) ecosystem, these tutorials serve as the primary gateway for adoption. However, a significant challenge persists: if a single command fails, an output diverges from the documentation, or a step lacks clarity, the majority of prospective users will abandon the project rather than file a bug report. To address this critical point of failure, the engineering team behind Drasi, a CNCF sandbox project supported by Microsoft Azure’s Office of the Chief Technology Officer, has pioneered a new methodology that treats documentation testing as a continuous monitoring problem solved by artificial intelligence.
The Catalyst for Change: The Late 2025 Infrastructure Shift
The transition toward AI-driven documentation testing was not merely a proactive innovation but a response to a catastrophic failure in manual oversight. In late 2025, GitHub implemented a significant update to its Dev Container infrastructure, which included raising the minimum required version of Docker. This backend modification, while standard for infrastructure maintenance, inadvertently severed the Docker daemon connection within the environments used for Drasi’s tutorials.
Because the Drasi team—a lean group of four engineers—relied on periodic manual testing, the failure went undetected for an extended window. During this period, every tutorial provided by the project was effectively broken. Any developer attempting to evaluate Drasi encountered an immediate technical wall, leading to a total cessation of successful onboarding. This incident highlighted the inherent fragility of documentation in a rapidly evolving cloud-native landscape where upstream dependencies, such as Docker, k3d, and Kubernetes distributions, change without warning.

The Anatomy of Documentation Failure
Following the infrastructure incident, the Drasi team conducted a post-mortem analysis to identify why traditional documentation maintenance fails. They identified two primary systemic issues: the "curse of knowledge" and "silent drift."
The curse of knowledge refers to the cognitive bias where experienced developers write instructions with implicit context that a novice lacks. For instance, a maintainer might write "wait for the query to bootstrap," assuming the user knows to monitor the system status via specific CLI commands. An AI agent or a new human user, however, follows instructions literally. If the "how" is not explicitly documented alongside the "what," the user becomes stranded.
Silent drift occurs because documentation, unlike source code, does not "fail loudly." When a configuration file is renamed in a codebase, the compiler or build pipeline triggers an immediate alert. Conversely, when documentation references an outdated filename or a deprecated CLI flag, the system remains silent. This drift accumulates over time as upstream dependencies update, eventually rendering the tutorial obsolete while the maintainers remain unaware.
Architecture of the Synthetic User
To combat these failures, the Drasi team developed a solution utilizing "synthetic users"—AI agents designed to replicate the behavior of a human developer encountering the project for the first time. This system is built upon a sophisticated stack including GitHub Actions, Dev Containers, Playwright, and the GitHub Copilot CLI.
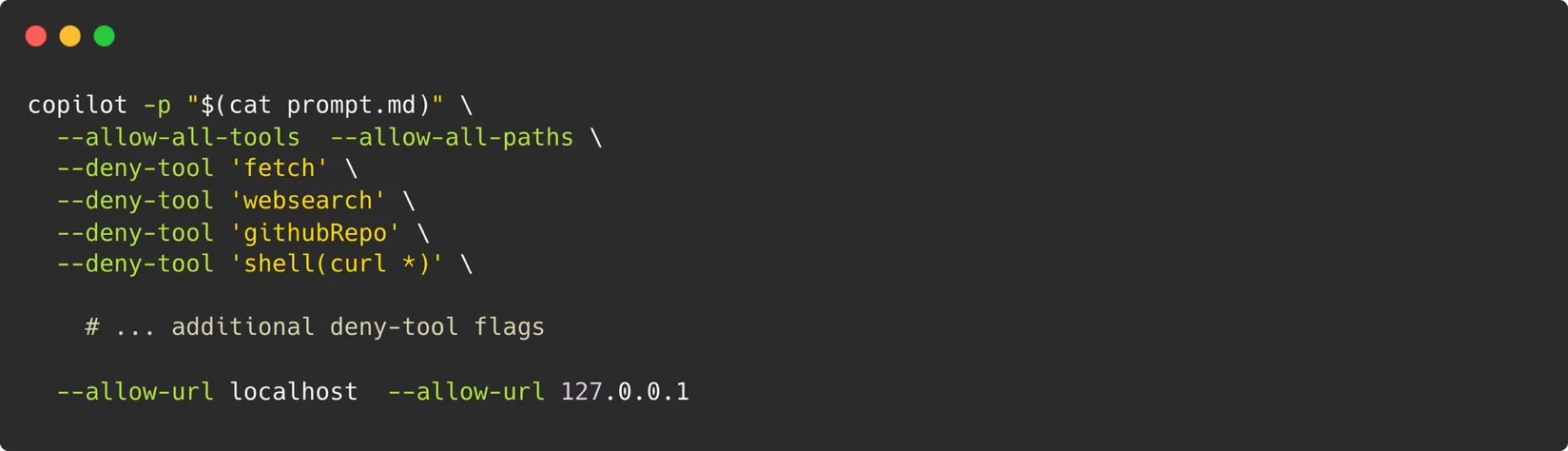
The core of the solution lies in the environment. To ensure the AI agent experiences exactly what a human user would, the team utilizes the same Dev Containers provided to the public via GitHub Codespaces. Within this isolated environment, the team invokes the GitHub Copilot CLI using a specialized system prompt. This prompt transforms the LLM into a goal-oriented agent capable of executing terminal commands, writing files, and running browser scripts.
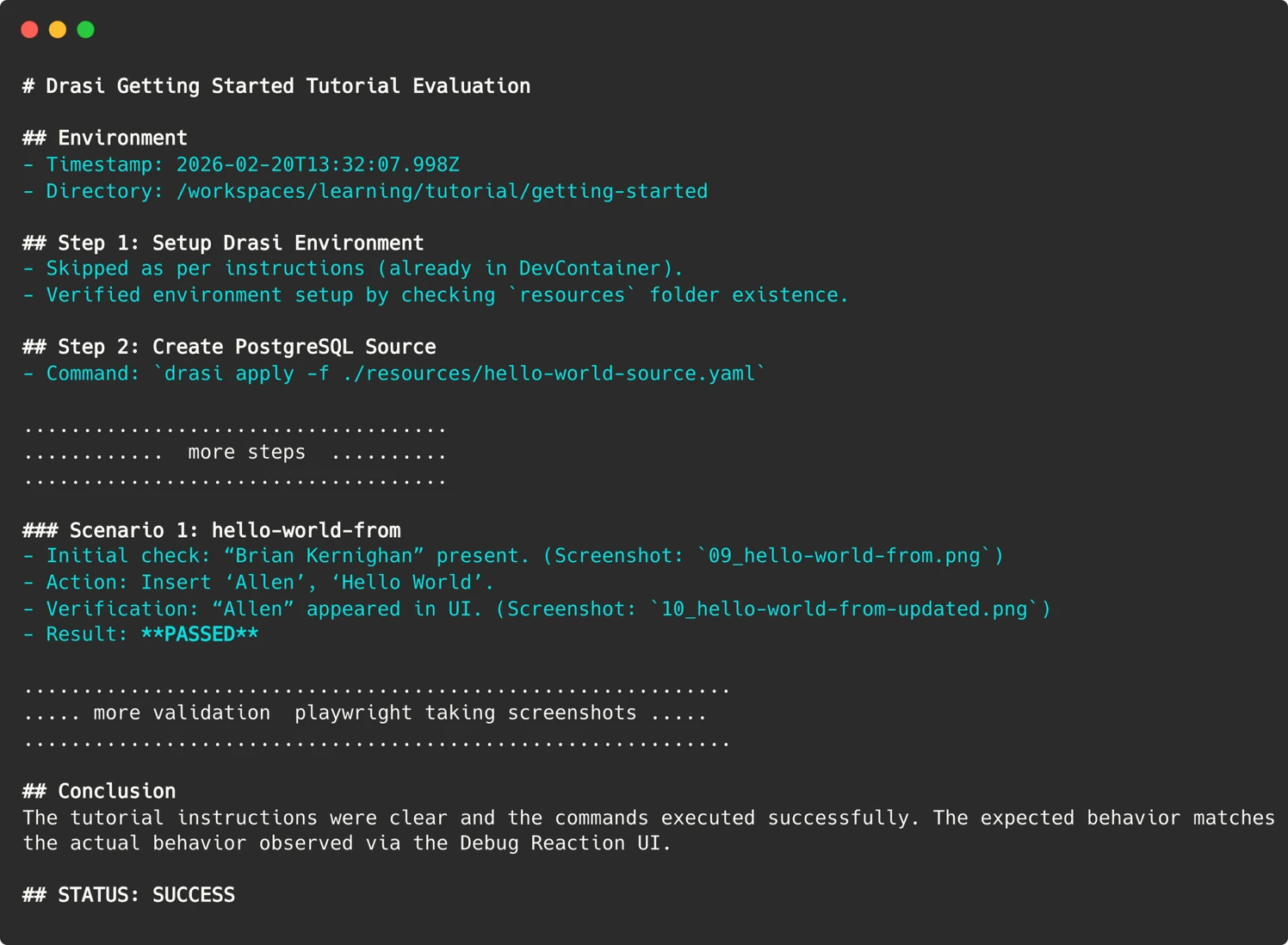
To facilitate interaction with web-based user interfaces—a common component of modern data tools—the team integrated Playwright into the Dev Container. This allows the AI agent to open web pages, click buttons, and capture screenshots. These screenshots are then compared against the expected visual outcomes described in the documentation, providing a layer of validation that traditional unit tests cannot achieve.
Security and the Sandbox Boundary
Implementing an AI agent with the authority to execute arbitrary terminal commands poses significant security risks. The Drasi team addressed this by establishing the container as the absolute security boundary. Rather than attempting to whitelist specific "safe" commands—a strategy that often fails against sophisticated LLMs—the team treats the entire Dev Container as an ephemeral, isolated sandbox.
The security model incorporates several layers of protection:
- Network Restrictions: No outbound network access is permitted beyond the localhost, preventing data exfiltration.
- Permission Scoping: The agent uses a Personal Access Token (PAT) restricted solely to "Copilot Requests" permissions.
- Ephemeral Lifecycle: Containers are destroyed immediately after a test run concludes.
- Maintainer Oversight: Any workflow triggered by a pull request from an external contributor requires manual approval from a project maintainer before execution.
Managing AI Non-Determinism
A primary hurdle in using Large Language Models (LLMs) for CI/CD pipelines is their probabilistic nature. Unlike traditional scripts, an AI agent may attempt different strategies to solve the same problem across different runs. To integrate this "fuzzy" logic into the binary environment of GitHub Actions, the Drasi team implemented a three-stage strategy:
First, they utilized model escalation. If the initial attempt (using a model like Gemini-Pro) fails, the system retries the task using a more robust model, such as Claude Opus. Second, they moved away from rigid pixel-matching for visual validation. Instead, the agent performs a semantic comparison of screenshots, identifying if the correct data fields are present even if the layout has shifted slightly. Finally, the team engineered specific "skip directives" and constraints to prevent the agent from wandering into unproductive debugging loops or attempting to configure external services that are outside the scope of the tutorial.
To bridge the gap between the agent’s narrative report and the GitHub Action’s exit code, the team uses a specific string-parsing technique. The agent is instructed to conclude its report with a clear "STATUS: SUCCESS" or "STATUS: FAILURE" marker. The CI pipeline then greps for this string to determine whether to pass or fail the build, successfully converting probabilistic reasoning into a binary signal.
Empirical Results and Bug Discovery
Since the implementation of the synthetic user system, the Drasi project has conducted over 200 automated sessions. This continuous monitoring has identified 18 distinct issues that had previously escaped human notice.
Significant findings included:
- Implicit Dependencies: The agent identified steps where the documentation assumed a tool was installed that was not actually present in the base Dev Container.
- Timing Vulnerabilities: The agent discovered "race conditions" in the tutorials, where a command would fail if executed too quickly after a previous step, leading to the addition of "wait" commands in the official guide.
- Upstream Changes: The system caught instances where a database container used in the tutorial had updated its default configuration, breaking the connection strings provided in the docs.
The team noted that by fixing these issues to satisfy the AI agent, they simultaneously improved the experience for human users. The "pedantic" nature of the AI forced the documentation to become more explicit, robust, and resilient.
Analysis of Implications for the Software Industry
The Drasi experiment represents a broader shift in the philosophy of Quality Assurance (QA). For small engineering teams, comprehensive manual testing of documentation is often financially and operationally impossible. By deploying synthetic users, a four-person team can achieve the output of a dedicated QA department.
This approach effectively converts documentation from a static asset into a monitored service. In the context of the CNCF and the wider open-source community, this could set a new standard for project health. Future contributors may look for "Documentation Passing" badges as a sign of a project’s reliability, similar to how they currently view build and test status badges.

Furthermore, this methodology highlights AI’s role as a "force multiplier" rather than a human replacement. The AI does not write the documentation; it validates the human-written intent against a real-world environment. This allows human engineers to focus on high-level architecture and feature development while the "tireless" AI agent handles the repetitive task of verifying that the "Getting Started" path remains clear of obstacles.
Conclusion and Future Outlook
The Drasi team now runs these synthetic user evaluations on a weekly basis, with each tutorial evaluated in parallel within its own sandbox. If a failure occurs, the system automatically files a GitHub issue, complete with terminal logs, screenshots, and a markdown report detailing the agent’s reasoning. This "time travel" debugging capability allows maintainers to see exactly where the user experience broke down.
As cloud-native environments continue to grow in complexity, the gap between "code that works" and "documentation that works" will likely widen. The integration of AI agents as synthetic users offers a scalable, secure, and highly effective solution to the problem of documentation drift. For the Drasi project, what began as a response to a broken Docker connection has evolved into a robust framework for ensuring that the first interaction a developer has with their project is a successful one. Other open-source maintainers facing similar resource constraints may find that the GitHub Copilot CLI, when paired with rigorous prompt engineering and containerization, is the key to maintaining a high-quality developer experience in an era of constant change.







{kind=link}