
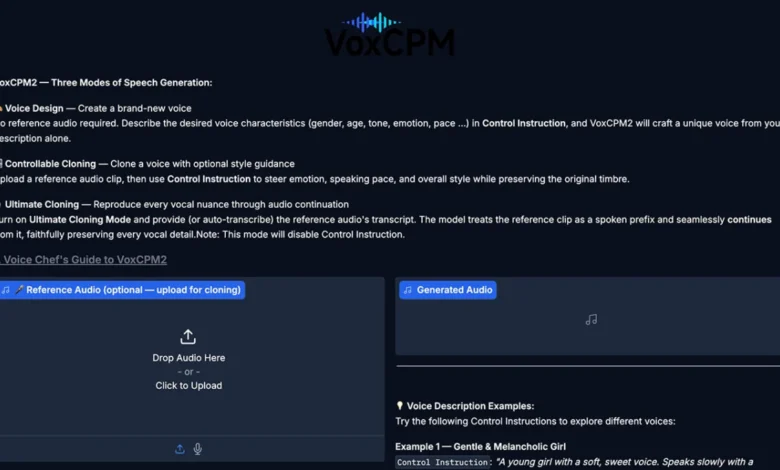
The field of open-source voice synthesis has long presented a tantalizing promise: the ability to generate realistic and versatile speech without the constraints of proprietary platforms or hefty subscription fees. However, for many users, the practical application of these models has fallen short of expectations. Common frustrations include flat, robotic-sounding output, complex and time-consuming setup processes, and voice cloning capabilities that, while functional for demonstrations, lack the fidelity and robustness required for real-world applications. Into this challenging arena steps VoxCPM2, an open-source text-to-speech (TTS) and voice cloning model developed by OpenBMB, which appears poised to address these long-standing limitations and offer a compelling alternative to established commercial solutions.
VoxCPM2 distinguishes itself by integrating a suite of advanced features directly into its architecture. These include local inference capabilities, sophisticated voice design options, controllable voice cloning, higher-fidelity cloning, and crucial streaming support. While it may not immediately dethrone industry leaders like ElevenLabs, VoxCPM2 represents a significant leap forward for accessible, high-quality AI voice generation, marking it as one of the most promising free alternatives to emerge in recent memory. For those seeking a broader understanding of the evolving TTS landscape, comparing VoxCPM2’s capabilities with established players like OpenAI’s text-to-speech offerings provides valuable context.
What Sets VoxCPM2 Apart in the Open-Source Arena
The current open-source TTS ecosystem is characterized by numerous projects, each often excelling in a specific niche. VoxCPM2, however, appears to be charting a course for a more comprehensive toolkit, aiming to address a wider range of user needs. Its departure from the traditional one-trick pony approach allows for a more adaptable and powerful user experience.
1. Foundational Text-to-Speech Capabilities
At its core, VoxCPM2 offers a robust text-to-speech engine. The standard generation process is designed for straightforward implementation, allowing users to convert textual input into spoken audio with relative ease. A key aspect of this functionality lies in the control parameters available to the user.
wav = model.generate(
text="Hello, this is VoxCPM2 running locally!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("output.wav", wav, model.tts_model.sample_rate)The cfg_value parameter directly influences how closely the generated speech adheres to the provided prompt, offering a dial for control over stylistic emphasis. Simultaneously, inference_timesteps presents a trade-off between processing speed and audio quality. This flexibility is invaluable, enabling rapid iteration during development and testing phases, while allowing for the generation of higher-fidelity audio when precision and polish are paramount. This granular control over output parameters is a significant advantage over many simpler open-source models that offer a more fixed output.
2. Innovative Voice Design Through Textual Descriptions
One of VoxCPM2’s most innovative features is its capacity for voice design based solely on textual descriptions. This moves beyond the necessity of cloning an existing voice, empowering users to synthesize entirely new vocal personas by describing their desired characteristics.
wav = model.generate(
text="(A young woman, gentle and sweet voice) Welcome to my blog post about free AI voice cloning!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("voice_design.wav", model.tts_model.sample_rate)This capability opens up a world of possibilities for rapid prototyping and creative exploration. Content creators, game developers, and educators can now quickly generate distinct voice styles without the need for pre-recorded reference audio. This is particularly advantageous when a specific vocal profile is envisioned but a suitable speaker or audio sample is unavailable, or when exploring a range of voice options before committing to a particular direction. This feature democratizes the creation of unique vocal identities, previously a complex and resource-intensive endeavor.
3. Controllable Voice Cloning for Practical Use
For users who possess a short audio sample of a desired voice, VoxCPM2 offers a streamlined voice cloning functionality. This is arguably the feature that will resonate most broadly with the TTS community, as it directly addresses the long-held aspiration of creating custom voiceovers.
wav = model.generate(
text="This is my cloned voice saying whatever I want.",
reference_wav_path="path/to/short_clip.wav",
)
sf.write("cloned.wav", wav, model.tts_model.sample_rate)The process is designed to be intuitive: provide a brief voice clip, and the model generates new text in a voice that closely mimics the reference. The success of this cloning depends on several factors, including the quality of the source audio, the clarity of the input prompt, and the inherent capabilities of the model itself. However, the workflow presented by VoxCPM2 is refreshingly direct, simplifying a process that has often been cumbersome in other open-source implementations. This feature holds significant potential for personalized content creation, accessibility tools, and even educational applications where familiar voices can enhance engagement.
4. Achieving Higher-Fidelity Voice Cloning
Beyond the standard cloning, VoxCPM2 introduces a mode specifically engineered for achieving higher fidelity. This approach is designed for users who prioritize precision and an exact reproduction of the original voice’s nuances.
wav = model.generate(
text="Every nuance of my voice is perfectly reproduced.",
prompt_wav_path="path/to/voice.wav",
prompt_text="Exact transcript of the reference audio here.",
reference_wav_path="path/to/voice.wav",
)
sf.write("ultimate_clone.wav", wav, model.tts_model.sample_rate)This advanced cloning pathway is more demanding, requiring not only the reference audio but also a precise textual transcription of that audio. This added step is a deliberate choice, facilitating a more accurate mapping of phonetic elements and prosody from the source to the synthesized speech. While it involves a greater investment of user effort, the payoff is a superior level of voice replication, catering to professional use cases where subtle vocal characteristics are critical. This meticulous approach positions VoxCPM2 as a viable option for applications demanding professional-grade voice cloning, bridging a gap that has often been filled by expensive proprietary services.
5. Enabling Seamless Streaming Output
The ability to generate audio in real-time through streaming is a critical differentiator for VoxCPM2, particularly for interactive applications. This functionality is essential for creating dynamic user experiences in virtual assistants, chatbots, and any system that requires immediate vocal feedback.
chunks = []
for chunk in model.generate_streaming(text="Streaming audio feels incredibly natural!"):
chunks.append(chunk)
wav = np.concatenate(chunks)
sf.write("streaming.wav", wav, model.tts_model.sample_rate)Streaming output transforms a voice model from a batch processing tool into a truly interactive component. The ability for the audio to begin playing before the entire waveform is generated significantly enhances the feeling of natural communication and responsiveness. This feature is not merely an enhancement; it is a foundational requirement for many modern AI-driven applications, making VoxCPM2 a more practical choice for developers aiming to build engaging, real-time experiences. Contextualizing this feature alongside other readily available text-to-speech applications highlights its significance in the broader market.
Command-Line Interface (CLI) Support for Enhanced Accessibility
Recognizing that not all users operate within a Python development environment, VoxCPM2 also provides a user-friendly Command-Line Interface (CLI). This offers a more direct and rapid entry point for users who wish to quickly test the model’s capabilities without the overhead of setting up a full development environment.
voxcpm design --text "Your text here" --output out.wavThis CLI support, while seemingly a minor detail, is a significant aspect of the project’s commitment to accessibility and ease of use. For individuals evaluating the potential of VoxCPM2, or for those who prefer command-line operations, this integrated tooling streamlines the testing and deployment process. Good tooling is often a deciding factor for open-source projects, and VoxCPM2’s inclusion of a functional CLI demonstrates a thoughtful approach to user experience.
Practical Considerations and Broader Implications
The primary appeal of VoxCPM2 lies in its ability to deliver high-quality AI voice generation without the financial barriers associated with commercial subscriptions, API usage fees, or restrictive closed platforms. By enabling robust local processing, comprehensive voice cloning, sophisticated voice design, and real-time streaming, VoxCPM2 significantly broadens the accessibility of advanced TTS technology. This democratization of tools empowers a wider range of individuals and organizations to experiment with and integrate AI voices into their projects, fostering innovation across various sectors.
The comparison to ElevenLabs, while not claiming direct parity, underscores the project’s ambition: to demonstrate that polished, commercial-grade voice generation is no longer exclusively the domain of paid services. For those exploring more lightweight, browser-based TTS solutions, understanding the landscape of existing applications provides further context for VoxCPM2’s advancements.
Several technical details, as highlighted by the project’s documentation, further bolster VoxCPM2’s credibility and potential for practical application. These include:
- Underlying Architecture: The model is built upon advanced deep learning architectures, suggesting a strong foundation for generating nuanced and natural-sounding speech. Specific architectural details, often found in research papers accompanying such projects, would provide further insight into its capabilities.
- Training Data and Methodology: The scale and diversity of the training data used are critical for a model’s performance. Open-source projects often provide details on their data sources and training methodologies, which can offer clues about the model’s robustness and potential biases.
- Performance Benchmarks: While the article doesn’t provide specific benchmarks, the inclusion of features like high-fidelity cloning and streaming implies that the developers have focused on optimizing performance metrics such as latency, audio quality (e.g., MOS scores), and resource utilization.
- Scalability and Integration: The emphasis on local inference and streaming suggests that the model has been designed with scalability and integration into larger applications in mind. This is crucial for developers looking to deploy VoxCPM2 in production environments.
These details are not merely technical minutiae; they collectively push VoxCPM2 beyond the realm of simple demonstration tools. They indicate a deliberate effort to create a platform that can be tuned, automated, and integrated into sophisticated workflows. The availability of the project on GitHub and Hugging Face provides the essential resources for developers and researchers eager to explore its full potential and contribute to its ongoing development. The open-source nature of VoxCPM2 fosters transparency and community-driven improvement, a hallmark of successful collaborative software development. As the technology matures, it is likely to find adoption in diverse fields, from personalized educational content and assistive technologies to innovative marketing campaigns and interactive entertainment.





{kind=link}