
Last October, amidst the bustling energy of Lisbon, a stark realization hit me in a hotel room the night before a crucial demo. Our team had poured four months into developing a project management tool, and as I prepared to showcase our work, the hotel’s unreliable Wi-Fi rendered our meticulously crafted application a blank screen with a spinning loader, followed by a frustrating timeout error. This was not a minor inconvenience; it was a public demonstration of a fundamental flaw.
A quick tether to my phone revealed a shaky connection. The app loaded, but each interaction was met with a two-second delay – a spinner for creating a task, another for moving it between columns. The thought was almost comical in its irony: a sophisticated stack comprising a React frontend, Node.js backend, PostgreSQL database, Redis cache, and a GraphQL API with six resolvers for the task board, all failing to display our own data without a round-trip to a server thousands of miles away. It was this moment of professional embarrassment that ignited my serious exploration of local-first architecture.
Initially, I, like many seasoned developers, dismissed local-first as an academic pursuit. The seminal 2019 paper by Ink & Switch, "Local-First Software," which outlined seven ideals—fast, multi-device, offline, collaboration, longevity, privacy, and user ownership—felt more like a wish list than actionable engineering requirements. The tooling in 2019 was indeed nascent, but my skepticism also stemmed from a comfortable adherence to familiar architectures. However, after shipping three production apps using local-first patterns and wisely removing it from two others where it proved ill-suited, I’ve developed a pragmatic, if opinionated, perspective. This article aims to distill those earned insights for developers who, like myself, have witnessed enough technological trends to approach any purported "silver bullet" with a healthy dose of skepticism.
What “Local-First” Actually Means (And The Confusion That Won’t Die)
A persistent misconception surrounding local-first architecture is its conflation with offline-first approaches or the simple addition of service workers for caching. This misunderstanding, frequently perpetuated in conference talks, obscures the true nature of local-first development.
Offline-first applications are designed to function gracefully during network disruptions, but the server remains the definitive source of truth. When connectivity is restored, the server’s data takes precedence. Cache-first strategies, often implemented with service workers, are primarily performance optimizations, serving stale data more rapidly but not fundamentally altering data ownership. Progressive Web Apps (PWAs) are a delivery mechanism, offering installability and enhanced user experiences, but they are not a data architecture.
Local-first, conversely, is fundamentally a data architecture. In this model, a user’s device holds the primary copy of their data. Applications read from and write to a local database, enabling instantaneous rendering and seamless background synchronization with servers or other devices. Servers, when present, function as synchronization peers with specific authorities (authentication, backup, access control), rather than as absolute gatekeepers.
The core tenet of local-first, as articulated by Ink & Switch, is that "The client is not a thin view requesting permission to show data. The client is a node in a distributed system with its own database." This seemingly subtle distinction triggers a profound shift in how entire technology stacks are conceived and built.
Be Honest Early: When You Should Not Do This
It’s crucial to address upfront when local-first is not the appropriate solution. My own experience, and that of many colleagues, highlights the pitfalls of forcing this architecture onto unsuitable projects. A six-week endeavor to implement local-first for an internal analytics dashboard at a previous job proved to be a misallocation of resources. The data was inherently server-generated, rendering client-side replication redundant.
Local-first is a poor fit for applications where data is primarily server-generated, such as analytics dashboards, social media feeds, or search results, where traditional API-driven consumption is efficient and effective. It is also unsuitable for systems demanding stringent transactional consistency, like banking, payment processing, or inventory management. These applications require ACID guarantees from a single authoritative database to prevent financial losses or critical errors due to eventual consistency.
Furthermore, it represents over-engineering for simple CRUD applications without offline or collaboration requirements. Deploying a sync engine for an internal admin panel used by a handful of users within an office network with stable internet is unnecessary complexity. Finally, it is practically infeasible for datasets so massive that they cannot be accommodated on client devices.
However, local-first architecture truly shines in applications like note-taking, document editing, collaborative design tools, project management, and field applications operating with unreliable connectivity. Crucially, it excels in scenarios where data privacy is a significant selling point and where real-time collaboration is paramount. Essentially, it is ideal for user-generated data that benefits from immediate interaction and resilience against server outages.
A pragmatic approach is not necessarily to adopt local-first wholesale. I’ve found the most success in integrating local-first patterns into specific features within otherwise traditional applications, such as implementing offline draft capabilities in a blog editor or enabling real-time collaborative notes within a standard REST-based project management tool. The "spectrum of local-first" is a tangible reality, and initiating with a single feature is a recommended starting point for adoption.
Replicas, Not Requests
For those familiar with Git, the mental model of local-first development will resonate strongly. Version control systems like SVN, with their centralized architecture, relied on a single server for commits and history, rendering the system inaccessible when the server was down. Git, by contrast, provides each developer with a full local clone, enabling local commits, branching, and merging. The remote repository serves as a crucial synchronization point, but it is not the sole repository of truth.
Local-first web development mirrors this Git-like paradigm for application data. Each client device maintains a replica—either full or partial—of relevant data. Writes are executed locally, and synchronization occurs seamlessly in the background through push/pull mechanisms. Conflicts are managed via predefined merge strategies.
The practical implications of this shift are profound. The need for data fetching libraries like React Query or SWR diminishes, as data is accessed directly from the local database. State management solutions like Redux or Zustand, often employed for server-derived state, become less critical, with the local database serving as the primary state source. Routing no longer necessitates API calls, and authentication paradigms evolve, as the server is no longer the sole arbiter of permissions for every data read.
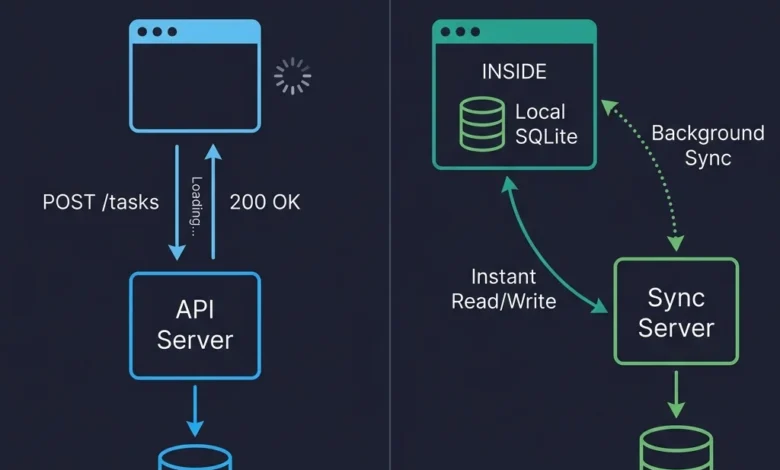
Consider a simple task creation function. In a traditional request/response architecture, this involves an API call, waiting for a response, and then updating the UI. In a local-first implementation, it’s a direct write to the local SQLite database, with the UI updating instantly as it reads from the same local source. Synchronization occurs asynchronously, eliminating loading states and complex optimistic update logic.
The visual distinction between traditional request/response architecture and local-first architecture underscores this fundamental shift. In the former, user interactions are characterized by a cycle of request, wait, and render. In the latter, reads and writes are direct interactions with the local database, with synchronization happening imperceptibly in the background.
Where Data Lives on the Client
Traditional client-side storage mechanisms like localStorage are inadequate for local-first applications. Its synchronous nature blocks the main thread, its storage capacity is limited to 5-10 MB, and it only stores strings, making it suitable only for basic preferences.
IndexedDB, while present in all browsers and asynchronous, suffers from a notoriously cumbersome API, making direct usage challenging. While it can handle hundreds of megabytes of data, its developer experience is far from ideal. Modern local-first development largely bypasses it in favor of more robust solutions.
The current vanguard of client-side data storage is SQLite compiled to WebAssembly (WASM). This powerful combination, coupled with the Origin Private File System (OPFS), provides web applications with a genuine relational database in the browser, supporting full SQL queries, transactions, and indexes.
OPFS, a newer API, enables sandboxed file system access with high-performance synchronous operations within Web Workers, which is precisely what SQLite WASM requires. Prior to OPFS, persisting SQLite data to IndexedDB was a slower and more fragile process.
Initializing a database with SQLite WASM typically involves libraries like wa-sqlite. The process generally includes initializing the SQLite API, setting up a Virtual File System (VFS) that utilizes OPFS for persistent storage, and then opening a database file. This setup allows for direct SQL operations and schema definition.

import SQLiteAPI from 'wa-sqlite';
import OPFSCoopSyncVFS from 'wa-sqlite/src/examples/OPFSCoopSyncVFS.js';
async function initDatabase()
const module = await SQLiteAPI.initialize();
const vfs = new OPFSCoopSyncVFS('pm-tool-db');
await vfs.initialize(module);
const db = await module.open_v2('workspace.db');
// HACK: wa-sqlite doesn't handle concurrent writes well on Safari,
// so we serialize through a queue. See vlcn-io/wa-sqlite#247
await module.exec(db, `PRAGMA journal_mode=WAL`);
await module.exec(db, `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
assignee_id TEXT,
project_id TEXT NOT NULL,
position REAL DEFAULT 0,
created_at TEXT DEFAULT (datetime('now')),
updated_at TEXT DEFAULT (datetime('now'))
)
`);
return db;
In production environments, wrapping all database access within a write queue that serializes mutations is a critical practice. Logging every failed write to an error tracking service like Sentry, along with the scrubbed SQL statement, is essential for debugging database issues within a user’s browser.
A notable challenge is the nuanced behavior of OPFS implementations across different browsers. Safari, for instance, has exhibited subtle differences from Chrome, including silent failures of createSyncAccessHandle() in certain iframe contexts. These issues necessitate fallback mechanisms, such as reverting to IndexedDB-backed persistence on Safari, which, while slower, ensures functionality. Recent Safari updates have reportedly addressed some of these concerns, but verification remains ongoing.
| Storage | Good For | Watch Out For |
|---|---|---|
| IndexedDB | Broad compatibility, moderate data | Terrible DX, no SQL, verbose |
| OPFS + SQLite WASM | Relational data, complex queries, serious apps | Safari quirks, ~400KB bundle addition |
| PGlite (Postgres in WASM) | Full Postgres compatibility on client | Newer, larger bundle, still maturing |
Libraries like cr-sqlite, which integrate Conflict-free Replicated Data Types (CRDTs) directly into SQLite, offer intriguing possibilities but remain in early stages for production use, presenting challenges in debugging CRDT state within SQLite.
The Part That’s Actually Hard
While storing data locally is a well-defined problem, reliably synchronizing it across devices and users is where the true complexity lies. Reconciling independent read and write operations across multiple replicas necessitates robust synchronization mechanisms. Several approaches exist, with Conflict-free Replicated Data Types (CRDTs) and database replication being the most prominent.
CRDTs are data structures engineered to merge concurrent edits without conflicts, offering mathematical guarantees. Yjs stands out as a popular JavaScript implementation, particularly effective for real-time collaborative text editing. Its integration into collaborative document editors has yielded generally positive experiences, though challenges in conflict resolution persist.
Setting up a shared Yjs document typically involves instantiating a Y.Doc and using a WebsocketProvider to connect to a synchronization server. Data structures like Y.Map are then used to represent and manage the application data, with observers triggering UI updates upon data changes.
import * as Y from 'yjs';
import WebsocketProvider from 'y-websocket';
const ydoc = new Y.Doc();
const provider = new WebsocketProvider(
'wss://sync.our-app.dev',
'workspace-a1b2c3d4',
ydoc
);
const tasks = ydoc.getMap('tasks');
// Add a task
const task = new Y.Map();
task.set('title', 'Review Q3 roadmap draft');
task.set('completed', false);
task.set('assignee', 'maria');
// TODO: type this properly once; yjs exports better TS types
// for nested maps. For now, this works fine.
tasks.set('f47ac10b-58cc-4372-a567-0e02b2c3d479', task as any);
tasks.observeDeep(() =>
// Re-render UI. In practice, I debounce this to ~16ms
// because observeDeep fires a LOT during active collaboration
renderTaskList(tasks.toJSON());
);Automerge, another significant CRDT library, leverages Rust for its backend and employs a document-oriented model. Loro, a newer Rust-based alternative, claims superior performance.
Database replication offers a more straightforward approach for many applications that do not require Google Docs-level real-time text editing. This involves replicating rows between a server database (e.g., PostgreSQL) and a client database (e.g., SQLite), with a synchronization engine managing the data flow.
PowerSync facilitates one-way replication from PostgreSQL to client SQLite, with a write-back path for mutations. ElectricSQL aims for more ambitious active-active synchronization between PostgreSQL and SQLite. While PowerSync demonstrated greater stability during my evaluation in early 2026, ElectricSQL’s architectural approach holds significant potential if executed effectively.
Triplit presents a unique full-stack database solution where synchronization is intrinsic, abstracting the distinction between client and server databases. Its developer experience has been notably positive in initial prototypes.
Event sourcing, which synchronizes a log of mutations rather than the current state, is utilized by LiveStore. While intellectually appealing, reconstructing state from an event log introduces complexity that may not be necessary for many applications. Event sourcing is often over-recommended for general application development and is better suited for audit logs and specific domains.
Conflicts: The Thing Everyone’s Afraid Of
The prospect of conflict resolution often evokes apprehension. However, experience has shown it to be a manageable challenge, contingent upon careful consideration of the specific data model. Conflicts arise when multiple replicas independently modify data without awareness of each other’s changes.
An initial, naive approach to conflict resolution might involve simply accepting the remote version, leading to silent data loss for local changes. A more effective strategy is Last-Write-Wins (LWW) applied at the field level, rather than the record level. When different fields are modified concurrently, both changes are retained. Conflicts truly emerge when the same field is altered, in which case the modification with the later timestamp prevails.
interface FieldValue boolean;
// ISO timestamp with enough precision to break most ties
updatedAt: string;
// Client ID as tiebreaker when timestamps match.
// This happens more often than you'd think.
clientId: string;
function pickWinner(a: FieldValue, b: FieldValue): FieldValue
const timeA = new Date(a.updatedAt).getTime();
const timeB = new Date(b.updatedAt).getTime();
if (timeA !== timeB) return timeA > timeB ? a : b;
// Deterministic tiebreaker when timestamps match
return a.clientId > b.clientId ? a : b;
// In practice, I apply this per-field across the whole record.
function mergeTask(local: Record<string, FieldValue>, remote: Record<string, FieldValue>)
const merged: Record<string, FieldValue> = ;
const allKeys = new Set([...Object.keys(local), ...Object.keys(remote)]);
for (const key of allKeys)
if (!local[key]) merged[key] = remote[key]; continue;
if (!remote[key]) merged[key] = local[key]; continue;
merged[key] = pickWinner(local[key], remote[key]);
return merged;
This field-level LWW approach effectively resolves approximately 95% of conflicts without user intervention. For textual data, the situation is more complex, often necessitating CRDTs.
A more insidious issue is semantic conflicts, where data merges structurally but results in a nonsensical state. For instance, two users booking the same meeting slot with different meeting details. Field-level merging accepts both writes, but a double-booking occurs. Addressing semantic conflicts requires application-level validation on the server during synchronization.
The proposed solution involves the server validating data against domain invariants before accepting it into the primary database. Instead of outright rejection, violations are flagged. When a client pushes mutations during sync, the server runs them through a constraint validation layer.
interface SyncViolation
type: 'scheduling_conflict'
async function validateSyncBatch(
mutations: SyncMutation[],
serverDb: Database
): Promise< accepted: SyncMutation[]; violations: SyncViolation[] >
const accepted: SyncMutation[] = [];
const violations: SyncViolation[] = [];
for (const mutation of mutations)
if (mutation.table === 'calendar_events')
// Check for double-booking
const overlapping = await serverDb.query(
`SELECT id, title FROM calendar_events
WHERE room_id = ? AND id != ?
AND start_time < ? AND end_time > ?`,
[mutation.data.room_id, mutation.data.id,
mutation.data.end_time, mutation.data.start_time]
);
if (overlapping.length > 0)
violations.push(
type: 'scheduling_conflict',
recordId: mutation.data.id,
description: `Conflicts with "$overlapping[0].title"`,
conflictingRecords: overlapping.map(r => r.id),
detectedAt: new Date().toISOString()
);
// Still accept the write, but flag it
// The alternative is rejecting it, but then the user's
// local state and server state diverge, and that's worse
accepted.push(mutation);
continue;
accepted.push(mutation);
return accepted, violations ;
Accepting the conflicting write and flagging it, rather than rejecting it outright, prevents state divergence and the creation of ghost records on the client. The client then presents a non-blocking notification, allowing the user to resolve the conflict. This approach is suitable for scenarios where a brief window of conflicting data is tolerable, but not for systems requiring strict transactional integrity.
For CRDTs like Yjs, character-level merging for text is highly effective. However, merging structured data can yield unexpected results. Post-merge deduplication steps might be necessary. In most application contexts, surfacing conflicts to users in a Git-like manner is inadvisable, as users prefer the application to manage resolutions. High-stakes content, such as legal documents, may necessitate user intervention.
As of mid-2026, the landscape of synchronization tools includes:
- Yjs: The most mature CRDT library, ideal for real-time collaborative editing.
- Automerge: A robust, Rust-backed CRDT with a document-oriented approach.
- PowerSync: Recommended for teams with existing PostgreSQL backends seeking offline support, offering a stable and understandable synchronization model.
- ElectricSQL: Ambitious in its pursuit of active-active replication, showing promise but requiring further maturity.
- Triplit: An intriguing full-stack database with built-in synchronization, impressing in early prototypes.
- Zero: A query-based synchronization approach, evolving from Replicache.
- TinyBase: A lightweight reactive store suitable for smaller applications or prototyping.
- PGlite: Offers full PostgreSQL compatibility within the browser, pointing towards future integration possibilities.
Given the rapid evolution of this field, abstracting the synchronization layer is prudent to mitigate the risk of architectural lock-in with any single tool.
Building A Real App: Architecture, Auth, And Migrations
A practical local-first application architecture typically involves a React frontend, a synchronization engine like PowerSync, client-side SQLite via wa-sqlite persisted to OPFS, and a backend service such as Supabase for authentication and PostgreSQL. Yjs is reserved for scenarios demanding rich text collaboration.
Component code in such an architecture often appears remarkably simple. For instance, fetching tasks via a live query from a local SQLite database eliminates the need for loading states, explicit invalidation, or complex optimistic update logic.

import useLiveQuery from '@powersync/react';
import db from '../lib/database';
function TaskBoard( projectId : projectId: string )
const tasks = useLiveQuery(
`SELECT * FROM tasks WHERE project_id = ? AND archived = 0 ORDER BY position`,
[projectId]
);
async function addTask( string)
await db.execute(
`INSERT INTO tasks (id, title, project_id, position, created_at)
VALUES (?, ?, ?, ?, datetime('now'))`,
[crypto.randomUUID(), title, projectId, tasks.length]
);
// That's it. useLiveQuery picks up the change automatically.
// No invalidation, no refetch, no loading state.
// No isLoading check. Data is local. It's always there after the first sync.
return (
<div>
tasks.map(task => <TaskCard key=task.id task=task />)
<NewTaskInput onSubmit=addTask />
</div>
);
This contrasts sharply with the more verbose code required for traditional React Query and REST equivalents, which would necessitate handling loading states, error states, optimistic updates with rollback, and cache invalidation.
Auth In A Local-First World
Authentication in local-first applications largely mirrors traditional methods, employing JWT tokens, OAuth flows, and session management. The authentication token primarily secures the synchronization connection rather than individual requests. Offline access is facilitated because the data is already present locally, having been authenticated during the initial synchronization.
Authorization, however, presents a more complex challenge. Relying on client-side code to conceal unauthorized data is insecure, as the client is not a trusted boundary. Data security must be enforced at the synchronization layer. Sync rules or "shapes" define which data replicas are transmitted to specific clients. Server-side validation of client writes against authorization rules is crucial before they are applied to the primary database.
End-to-end encryption (E2EE) is a natural complement to local-first architecture, enabling data to be encrypted on the client before synchronization. Servers then store and relay encrypted blobs, ensuring data privacy.
Schema Migrations On A Thousand Devices
Managing schema migrations across numerous client devices, each potentially running a different version of the application, requires a deliberate strategy. A client-side migration runner that checks a version number at application startup is essential.
const MIGRATIONS = [
version: 1,
sql: `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
project_id TEXT NOT NULL,
created_at TEXT DEFAULT (datetime('now'))
);
`
,
version: 2,
// Added priority and due_date in sprint 4
sql: `
ALTER TABLE tasks ADD COLUMN priority INTEGER DEFAULT 0;
ALTER TABLE tasks ADD COLUMN due_date TEXT;
`
,
version: 3,
// Denormalized assignee name for offline display.
// Yes, I know this is a trade-off. The JOIN was killing
// performance on low-end Android devices.
sql: `
ALTER TABLE tasks ADD COLUMN assignee_name TEXT DEFAULT '';
`
];
async function runMigrations(db: Database)
await db.execute(`
CREATE TABLE IF NOT EXISTS _schema_version (version INTEGER)
`);
const rows = await db.execute('SELECT version FROM _schema_version');
const currentVersion = rows.length > 0 ? rows[0].version : 0;
for (const migration of MIGRATIONS)
if (migration.version > currentVersion)
console.log(`Migrating local DB to v$migration.version`);
await db.execute('BEGIN');
try
await db.execute(migration.sql);
await db.execute(
'INSERT OR REPLACE INTO _schema_version (rowid, version) VALUES (1, ?)',
[migration.version]
);
await db.execute('COMMIT');
catch (err)
await db.execute('ROLLBACK');
// In production, this fires a Sentry alert with the
// migration version and error details
throw err;
Migrations should be designed to be additive, incorporating new columns or tables. Renaming or dropping columns should be avoided unless absolutely necessary, as older client versions may still sync data, leading to mismatches.
If I Were Starting A New Project Today
For a collaborative application requiring real-time features and offline support, my current recommendation involves React for the frontend, PowerSync for synchronization, SQLite via wa-sqlite on the client (persisted to OPFS with an IndexedDB fallback for Safari), and Supabase for its integrated PostgreSQL, authentication, and row-level security. Yjs would be employed solely for rich text collaboration needs.
For simpler applications prioritizing offline support and rapid reads over complex collaboration, a custom sync layer pushing/pulling from a REST API alongside a local SQLite database might be more efficient than a full-fledged sync engine.
I would currently avoid ElectricSQL or Zero for production, not due to inherent flaws, but because they require additional maturity before being considered for mission-critical applications. Past experiences with early-stage infrastructure, such as Meteor, have instilled a cautious approach to adopting novel technologies.
Performance: What’s Actually Fast and What Hurts
Reads are instantaneous in local-first applications. Querying a local SQLite database for thousands of records can be accomplished in milliseconds, without network latency or loading indicators. Writes are equally rapid, with local execution and reactive UI updates. Synchronization occurs seamlessly in the background.
The primary performance cost is incurred during initial synchronization. Bootstrapping a local replica on first load requires downloading potentially megabytes of data. Mitigation strategies include partial synchronization (e.g., syncing only active projects) and displaying a dedicated setup screen during the initial sync. Subsequent incremental updates are minimal.
Bundle size is a significant consideration, as SQLite compiled to WASM can add approximately 400KB gzipped to the JavaScript bundle. Lazy loading the database module with dynamic import() helps mitigate its impact on initial rendering.
Memory usage on mobile browsers with strict limits can also be a challenge, potentially leading to tab crashes with large databases. Strategies like minimizing synced datasets through partial replication and aggressive data pruning are essential.
Martin Kleppmann’s "Designing Data-Intensive Applications" remains an invaluable resource for understanding distributed data systems and their complexities.
Testing This Stuff
Testing local-first applications presents unique challenges compared to traditional architectures. Effective strategies include unit tests for merge logic, integration tests simulating concurrent client instances, and Playwright end-to-end tests that leverage context.setOffline(true) to mimic offline/online transitions.
Reproducing bugs related to specific timing during conflict resolution remains difficult. Detailed logging of synchronization events, including data transmitted, received, conflicts detected, and resolution methods, is crucial for debugging. Property-based testing with libraries like fast-check is particularly beneficial for CRDT logic, generating random operation sequences to verify convergence.
What I’m Watching, What Worries Me
The convergence of local-first architecture with AI holds significant promise, particularly in scenarios where models run locally, data remains on-device, and cloud AI is utilized with explicit consent and encryption. The "your data never leaves your device" paradigm is poised to become a key differentiator in the evolving software landscape.
However, fragmentation within synchronization protocols is a primary concern. The absence of a universal standard for synchronization poses risks, as reliance on proprietary solutions from smaller companies can lead to significant migration challenges if those solutions become obsolete. Abstraction of the synchronization layer is therefore a prudent measure.
The inherent architectural complexity of local-first—encompassing synchronization engines, conflict resolution, client-side migrations, and partial replication—is a double-edged sword. While it offers substantial benefits for experienced teams building appropriate applications, it can become a trap for those requiring simpler CRUD functionality.
The adage, "The best architecture is the one your team can debug at 2 AM," underscores the importance of a deep understanding of the chosen architecture’s failure modes. For teams embarking on local-first development, a phased approach, starting with a prototype and thoroughly investigating its breaking points, is highly recommended.
The journey of building my fourth local-first application, a collaborative planning tool, continues to provide valuable insights into the capabilities and nuances of this evolving architectural paradigm. For developers beginning their exploration, integrating local-first patterns into a single feature, starting with local SQLite and reactive queries, offers a tangible and often revelatory experience, demonstrating how applications can and should function.





{kind=link}