
Amazon Web Services Launches S3 Files to Bridge Object and File Storage for High-Performance Workloads
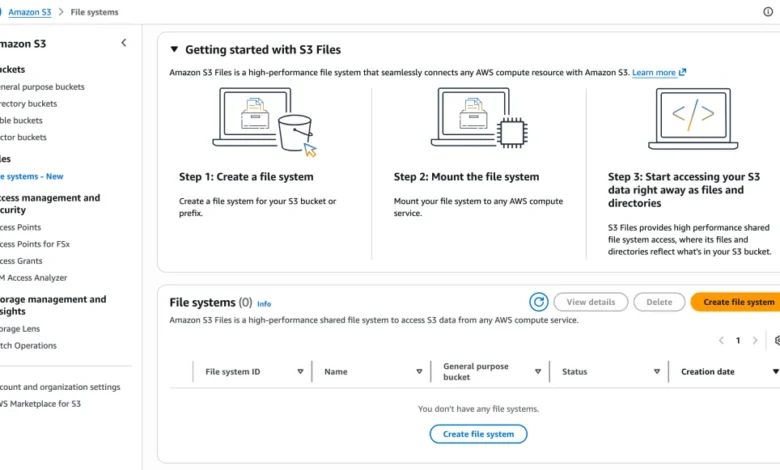
Amazon Web Services (AWS) has announced the general availability of Amazon S3 Files, a new file system interface designed to provide seamless connectivity between AWS compute resources and Amazon Simple Storage Service (S3). This release marks a significant shift in cloud storage architecture, as S3 Files allows Amazon S3 to function as a fully-featured, high-performance file system. By enabling general-purpose S3 buckets to be mounted as native file systems, AWS is addressing a long-standing technical challenge: the inherent architectural divide between object-based storage and hierarchical file systems.
The new service is engineered to allow changes made at the file system level to be automatically reflected within the corresponding S3 bucket. This bidirectional synchronization provides organizations with fine-grained control over data consistency and accessibility. Furthermore, S3 Files supports concurrent attachment to multiple compute resources, facilitating data sharing across large-scale clusters without the need for data duplication or manual synchronization scripts. This capability is expected to streamline workflows for production applications, machine learning (ML) model training, and the development of autonomous AI systems.

The Convergence of Object and File Storage Paradigms
For nearly two decades, cloud architects have operated under a clear distinction between object storage and file storage. Amazon S3, launched in 2006, revolutionized the industry by offering virtually unlimited scale and high durability through an object-based model. In this model, data is treated as discrete units (objects) stored in a flat address space. While ideal for web-scale data and long-term archiving, object storage traditionally lacked the interactive capabilities of a file system, such as the ability to modify specific bytes within a file or manage data through a nested directory structure.
Conversely, file systems like Amazon Elastic File System (EFS) and Amazon FSx provide the hierarchical structure and low-latency performance required by traditional applications. However, these systems often come with different cost structures and scaling considerations compared to S3. Until the launch of S3 Files, developers were frequently forced to choose between the cost-effective durability of S3 and the interactive performance of a dedicated file system. S3 Files effectively eliminates this trade-off by positioning Amazon S3 as a central data hub that can be natively consumed by any AWS compute instance, container, or serverless function.
Technical Specifications and Performance Architecture
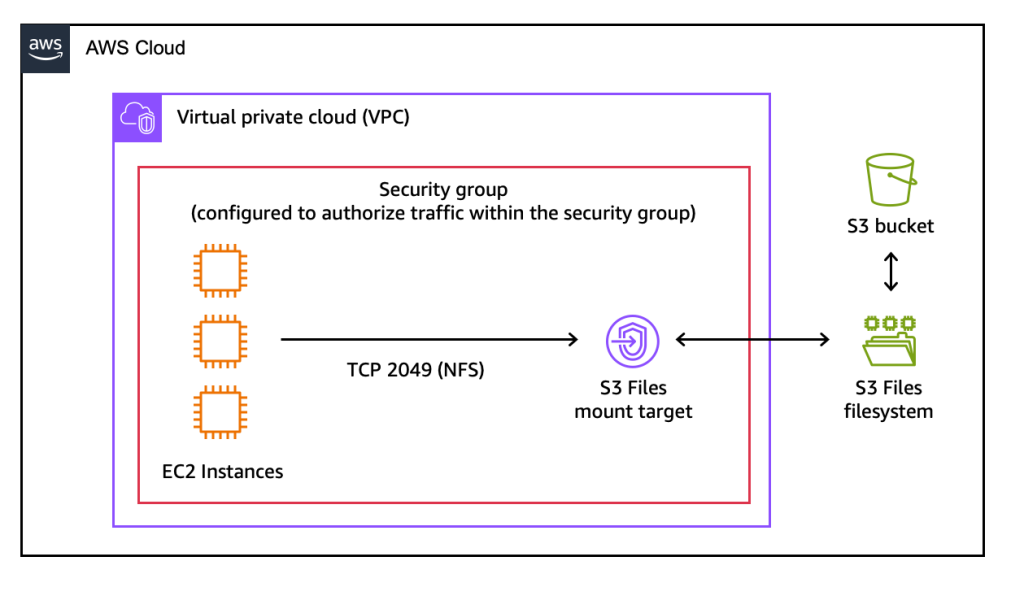
Amazon S3 Files is compatible with a wide array of AWS compute services, including Amazon Elastic Compute Cloud (EC2), Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), and AWS Lambda. The system presents S3 objects as standard files and directories, supporting Network File System (NFS) version 4.1 and higher. This allows for standard operations such as creating, reading, updating, and deleting files using familiar command-line tools and programming libraries.

Underpinning the performance of S3 Files is the integration of Amazon Elastic File System (EFS) technology. When a file system is created, S3 Files utilizes a high-performance storage tier to deliver sub-millisecond (approximately 1ms) latencies for active data. Metadata and frequently accessed file contents are cached on this high-performance tier to ensure rapid response times. For workloads involving large sequential reads or less frequent access, S3 Files intelligently serves data directly from Amazon S3 to maximize throughput and minimize costs.
The system also incorporates intelligent pre-fetching capabilities. By anticipating data access patterns, S3 Files can preemptively load data into the high-performance tier, reducing wait times for compute resources. Users maintain granular control over these settings, with the ability to decide whether to load full file data or metadata only, allowing for optimization based on specific workload requirements.
Chronology of AWS Storage Innovation
The introduction of S3 Files represents the latest milestone in a nearly twenty-year timeline of storage evolution at AWS:
- 2006: Launch of Amazon S3, establishing the cloud object storage category.
- 2008: Introduction of Amazon Elastic Block Store (EBS) for persistent block storage for EC2.
- 2012: Launch of Amazon Glacier (now S3 Glacier) for low-cost archival storage.
- 2015: Launch of Amazon EFS, providing a managed NFS file system for Linux workloads.
- 2018: Introduction of Amazon FSx, offering specialized file systems for Windows (FSx for Windows File Server) and high-performance computing (FSx for Lustre).
- 2021: Launch of Amazon S3 Multi-Region Access Points to accelerate global data access.
- 2024: Launch of Amazon S3 Files, bridging the gap between S3 durability and file system interactivity.
This progression demonstrates a clear trend toward breaking down the silos between different storage types, moving toward a unified data layer where the underlying storage format becomes transparent to the application.
Operational Workflow and Implementation
The implementation of S3 Files is designed to be straightforward for cloud administrators and developers. The process involves three primary steps, which can be executed via the AWS Management Console, Command Line Interface (CLI), or Infrastructure as Code (IaC) tools.
- Creation of the File System: A user selects an existing general-purpose S3 bucket to be exposed as a file system. During this phase, the system establishes the necessary links between the object store and the file system interface.
- Mount Target Discovery: S3 Files automatically creates mount targets, which act as network endpoints within a Virtual Private Cloud (VPC). These endpoints allow compute resources to communicate with the S3 file system securely.
- Mounting the Instance: Using standard Linux mount commands, the file system is attached to the compute resource. For example, a user can mount the S3 bucket to a local directory on an EC2 instance, after which standard file operations (e.g.,
ls,cp,mkdir) can be performed directly on S3 data.
Data consistency is managed through "close-to-open" consistency, a standard NFS behavior. When a file is modified and closed on one compute resource, the updates are synchronized back to the S3 bucket. Other resources mounting the same file system will see these changes upon opening the file, ensuring a reliable collaborative environment for distributed workloads.
Comparative Analysis of AWS File Services
With the addition of S3 Files, AWS now offers a comprehensive suite of file storage options, each tailored to specific use cases. Industry analysts suggest that S3 Files will fill a crucial niche between EFS and FSx.
- Amazon S3 Files: Best suited for workloads that require interactive, shared access to data already residing in S3. It is the primary choice for "agentic AI" systems, where AI agents use Python libraries or shell scripts to manipulate files, and for ML pipelines that process massive datasets stored as objects.
- Amazon EFS: Remains the standard for general-purpose Linux workloads, web serving, and content management systems where high IOPS and low latency are the primary requirements, independent of an S3 backend.
- Amazon FSx: Recommended for specialized requirements. FSx for Lustre serves high-performance computing (HPC) and GPU clusters, while FSx for NetApp ONTAP, OpenZFS, and Windows File Server provide feature-rich environments for migrating on-premises enterprise applications to the cloud.
Broader Industry Impact and Strategic Implications
The launch of S3 Files is expected to have a profound impact on how organizations manage "data gravity." Traditionally, moving large datasets from object storage to a high-performance file system for processing involved significant time and egress costs. By allowing compute resources to act on S3 data in situ, AWS is reducing the friction associated with data movement.
For the burgeoning field of Artificial Intelligence, S3 Files provides a vital infrastructure component. Modern AI development often involves "agentic" workflows, where autonomous agents interact with tools, scripts, and datasets. These tools are frequently designed to operate on local file systems. S3 Files allows these agents to work directly with petabyte-scale S3 data as if it were on a local disk, significantly accelerating the development cycle for AI-driven automation.
Furthermore, the pricing model for S3 Files—which includes charges for data stored in the file system tier, read/write operations, and S3 synchronization requests—offers a transparent way for enterprises to scale their storage costs in line with their active data usage rather than their total data footprint.
As cloud architectures continue to evolve toward more integrated and simplified models, S3 Files represents a definitive step toward a "data-first" approach. By eliminating the need to choose between the durability of S3 and the performance of a file system, AWS has provided a solution that simplifies the tech stack for thousands of organizations, potentially setting a new standard for cloud storage interoperability.
The service is currently available across all commercial AWS Regions. Detailed pricing information and technical documentation are available through the official AWS portal, providing a roadmap for organizations looking to modernize their data access strategies.







{kind=link}