
Building a Privacy-First Intelligence Layer: The Rise of Local AI in Customer Sentiment Analysis and Speech Recognition

The modern customer service landscape is defined by a massive influx of unstructured data, primarily in the form of recorded telephone conversations. In high-volume contact centers, thousands of hours of audio are generated daily, containing critical information regarding consumer satisfaction, product defects, and emerging market trends. Historically, the analysis of these recordings was a labor-intensive process, requiring manual review by quality assurance teams or the use of expensive, cloud-based transcription services. However, a new paradigm in localized artificial intelligence is enabling organizations to process this "audio goldmine" entirely on-premises. By integrating open-source models such as OpenAI’s Whisper, CardiffNLP’s RoBERTa, and BERTopic, developers have created a robust framework for transcribing, analyzing, and visualizing customer interactions without the data ever leaving the local hardware environment.
The Shift Toward Localized AI Architectures
The move toward local AI deployment is driven by three primary factors: data privacy, cost predictability, and operational independence. In an era of stringent data protection regulations, such as the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States, the transmission of sensitive customer voice data to third-party cloud providers presents a significant compliance risk. Call recordings often contain personally identifiable information (PII), ranging from names and addresses to financial details. Localized processing mitigates these risks by ensuring that the raw audio and its subsequent transcriptions remain within the organization’s secure perimeter.

Furthermore, the economic model of cloud-based AI—often based on per-minute transcription fees or per-token analysis costs—can become prohibitively expensive for large-scale operations. By utilizing open-source models that run on local GPUs or high-performance CPUs, companies can transition from a variable cost model to a fixed infrastructure investment. This shift also removes the dependency on internet connectivity and rate limits imposed by API providers, allowing for consistent, high-throughput processing of historical data archives.
Technical Chronology: From Waveform to Actionable Insight
The process of converting raw audio into a structured business intelligence dashboard follows a sophisticated multi-stage pipeline. This chronology begins with the ingestion of audio files and concludes with the generation of interactive visualizations that summarize the emotional state and topical concerns of the customer base.
1. High-Fidelity Transcription via Whisper
The first stage of the pipeline utilizes Whisper, a state-of-the-art automatic speech recognition (ASR) system. Unlike earlier ASR models that struggled with accents and background noise, Whisper was trained on a diverse dataset of 680,000 hours of multilingual audio. The technical innovation behind Whisper lies in its use of a Transformer-based encoder-decoder architecture.
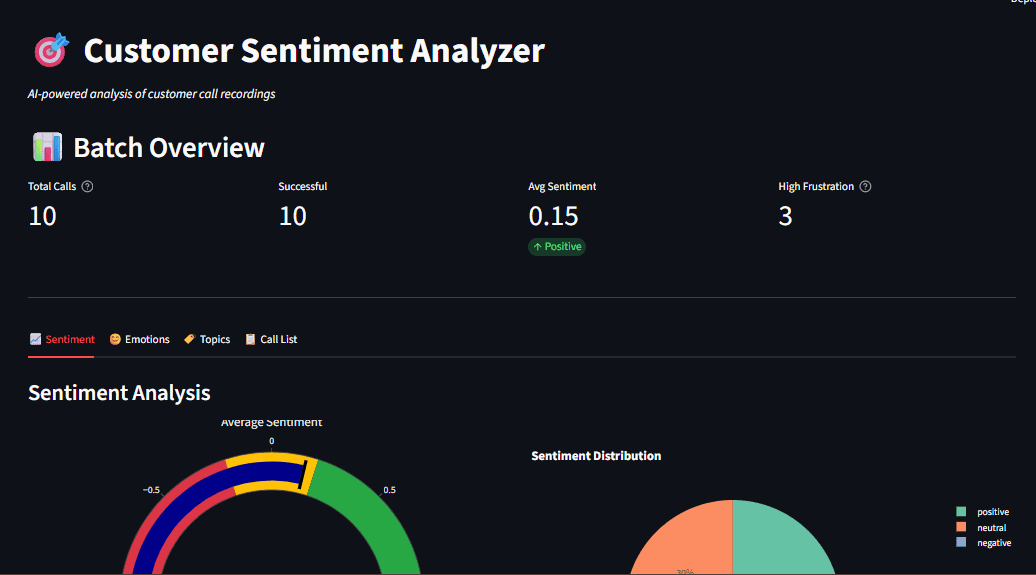
When an audio file is processed, it is first converted into a mel spectrogram—a visual representation of the audio frequencies as they change over time, adjusted to match the human ear’s logarithmic perception of sound. The Transformer encoder processes these spectrogram patches, while the decoder predicts the corresponding text sequence. This approach allows the system to maintain high accuracy even in the presence of the telephonic artifacts and ambient noise common in call center environments. Organizations can choose between various model sizes—ranging from the 39-million-parameter "tiny" model for rapid testing to the 1.55-billion-parameter "large" model for maximum precision.
2. Contextual Sentiment and Emotion Detection
Once the text is extracted, the system moves beyond simple transcription to understand the "how" of the conversation. Traditional sentiment analysis relied on lexicon-based methods, such as VADER, which simply counted positive and negative words. These methods frequently failed to grasp sarcasm, double negatives, or industry-specific context.
The modern localized approach employs RoBERTa (A Robustly Optimized BERT Pretraining Approach), specifically versions fine-tuned on conversational data. By using a Transformer architecture, the model analyzes the relationship between words in a sentence, allowing it to understand that "The service was not bad" carries a neutral-to-positive connotation, whereas a lexicon-based tool might flag "bad" as a purely negative signal. The system outputs a compound score ranging from -1 (extremely negative) to +1 (extremely positive), alongside specific emotional labels such as joy, anger, or frustration. This dual-layered analysis provides a more nuanced view of the customer experience than a simple "thumbs up or down" metric.
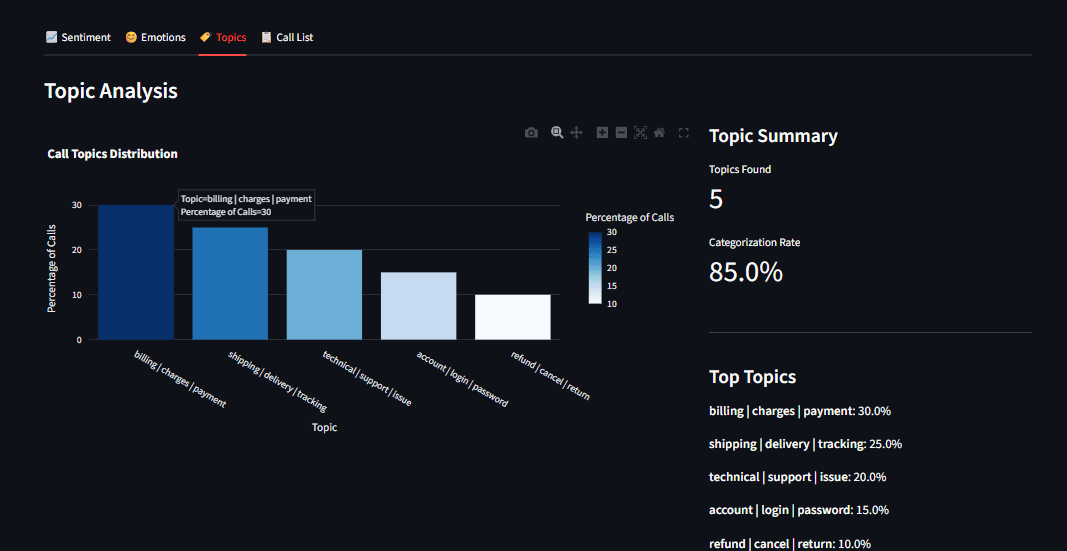
3. Unsupervised Topic Discovery with BERTopic
The final analytical stage involves identifying the "what" of the conversations. In large datasets, it is impossible for human analysts to pre-define every possible reason for a customer call. BERTopic solves this by using unsupervised machine learning to discover latent themes across thousands of transcripts.
The BERTopic workflow involves three distinct steps. First, it generates document embeddings using a pre-trained Transformer model, converting text into high-dimensional vectors where similar meanings are positioned close together. Second, it applies UMAP (Uniform Manifold Approximation and Projection) to reduce the dimensionality of these vectors, followed by HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) to group similar conversations into clusters. Finally, a class-based TF-IDF (Term Frequency-Inverse Document Frequency) procedure identifies the most representative keywords for each cluster. This allows the system to automatically flag emerging issues—such as a specific bug in a software update or a recurring logistics delay—without any prior manual tagging.
Supporting Data and Performance Benchmarks
The efficacy of localized AI is supported by the increasing efficiency of the underlying models. Benchmarks indicate that the "base" Whisper model can transcribe audio at approximately 10x to 20x real-time speed on modern consumer-grade GPUs, such as the NVIDIA RTX series. For instance, a 10-minute customer call can be transcribed in under 30 seconds with high accuracy.
In terms of sentiment analysis, Transformer-based models like RoBERTa consistently outperform traditional machine learning models (like Support Vector Machines or Naive Bayes) by a margin of 10-15% in F1-score accuracy, particularly in complex conversational datasets. The ability to run these models locally is further facilitated by quantization techniques, which reduce the memory footprint of the models (often to under 2GB) without significantly sacrificing predictive performance.
Operational Integration and User Interface
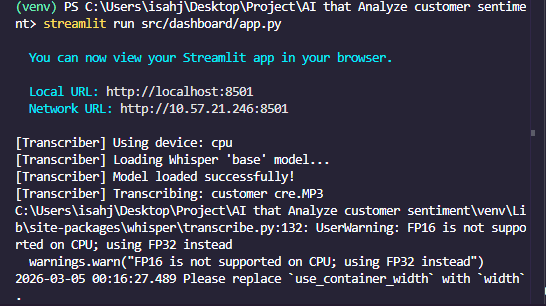
To make these complex AI outputs accessible to business stakeholders, the project utilizes Streamlit, an open-source framework that converts Python scripts into interactive web applications. The resulting dashboard serves as a command center for customer experience managers.
Key features of the integrated dashboard include:
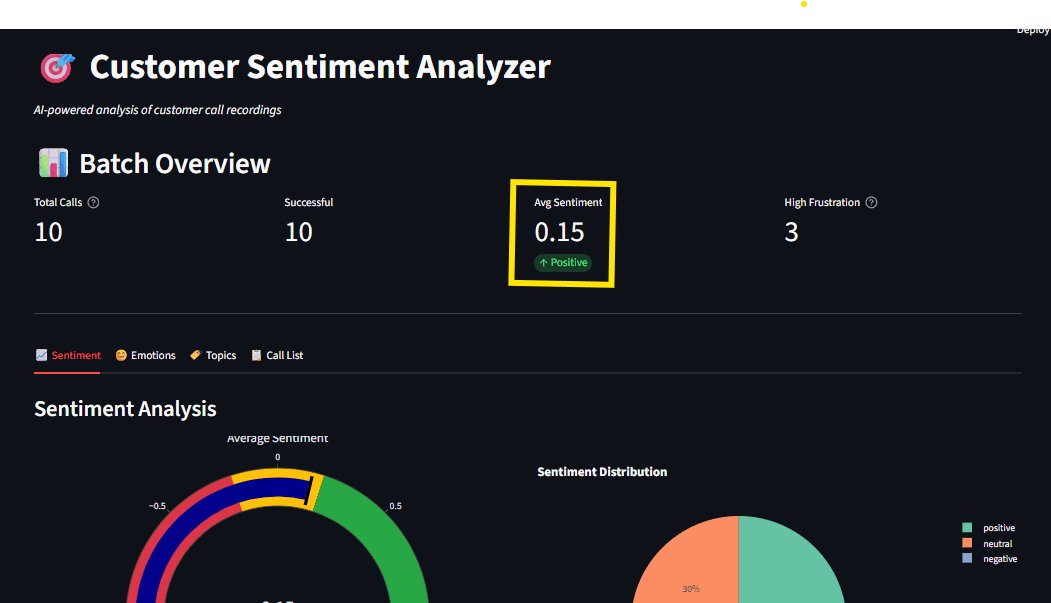
- Sentiment Gauges: Real-time visualization of the average sentiment score across all processed calls.
- Emotion Radars: A graphical representation of the emotional spectrum, helping managers identify if "anger" or "confusion" is the dominant negative emotion.
- Topic Distribution Charts: Bar charts and word clouds that highlight the most frequent reasons for contact.
- Transcript Exploration: A searchable interface that allows users to click on a specific topic or sentiment and read the corresponding timestamped transcript.
The use of @st.cache_resource in the application’s backend ensures that the heavy AI models are loaded into the system’s RAM only once, allowing for a responsive user experience as different files are uploaded and analyzed.
Broader Impact and Industry Implications
The democratization of high-performance, local AI tools represents a significant shift in the competitive landscape of business intelligence. Small and medium-sized enterprises (SMEs) now have access to the same analytical capabilities that were previously reserved for large corporations with massive cloud budgets and specialized data science teams.
Industry analysts suggest that the integration of local sentiment analysis will lead to several transformative outcomes:
- Proactive Churn Reduction: By identifying subtle shifts in customer sentiment over a series of calls, companies can intervene before a customer decides to cancel their service.
- Enhanced Training and Coaching: Call center supervisors can use emotion detection to identify specific calls where agents handled high-stress situations effectively, creating a library of "best practice" recordings.
- Rapid Product Feedback Loops: Engineering teams can receive automated reports on the most discussed product features or bugs within hours of a new release.
- Regulatory Compliance Monitoring: Automated systems can scan transcripts for required legal disclosures or "red flag" language, ensuring that agents adhere to industry regulations.
As hardware continues to evolve, with dedicated AI accelerators becoming standard in desktop and server processors, the performance gap between local and cloud AI will continue to narrow. This project serves as a foundational blueprint for organizations looking to build sovereign intelligence systems—tools that provide deep insights while maintaining absolute control over their most valuable asset: their data. The era of the "private AI" is no longer a theoretical possibility but a practical reality for the modern data-driven enterprise.








{kind=link}