
Modern Data Engineering Standards: Implementing Software Engineering Principles for SQL Reliability and Data Quality Automation

The landscape of data engineering is currently undergoing a fundamental transformation, shifting from a focus on static script execution to a more rigorous, software-centric methodology. For years, Structured Query Language (SQL) was treated as a secondary tool—a means to extract data that lacked the version control, testing frameworks, and automated deployment pipelines common in traditional software development. However, as organizations increasingly rely on real-time analytics to drive multi-million dollar decisions, the industry is adopting "SQL-as-Code" practices. This shift is designed to address a critical vulnerability in data pipelines: the "silent failure," where a query continues to run without error but produces incorrect or misleading results due to underlying data changes or unhandled edge cases.

The Evolution of the Data Pipeline Reliability
Historically, data analysts and engineers focused primarily on the immediate output of a query. If the SQL statement returned the expected rows in a development environment, it was often deemed ready for production. This approach, while fast, fails to account for the dynamic nature of modern data environments. Schema drift, late-arriving data, and unexpected null values can render a previously "perfect" query obsolete overnight.
To combat this, industry leaders are now advocating for a workflow that treats SQL logic with the same reverence as a Python or Java application. This involves a multi-step lifecycle: versioning the code in repositories like GitHub, wrapping logic in unit tests, and automating the entire process through Continuous Integration and Continuous Deployment (CI/CD) pipelines. By treating SQL like software, organizations can ensure that their data infrastructure is not only correct today but resilient against the changes of tomorrow.

Case Study: Identifying High-Value Customers at Amazon
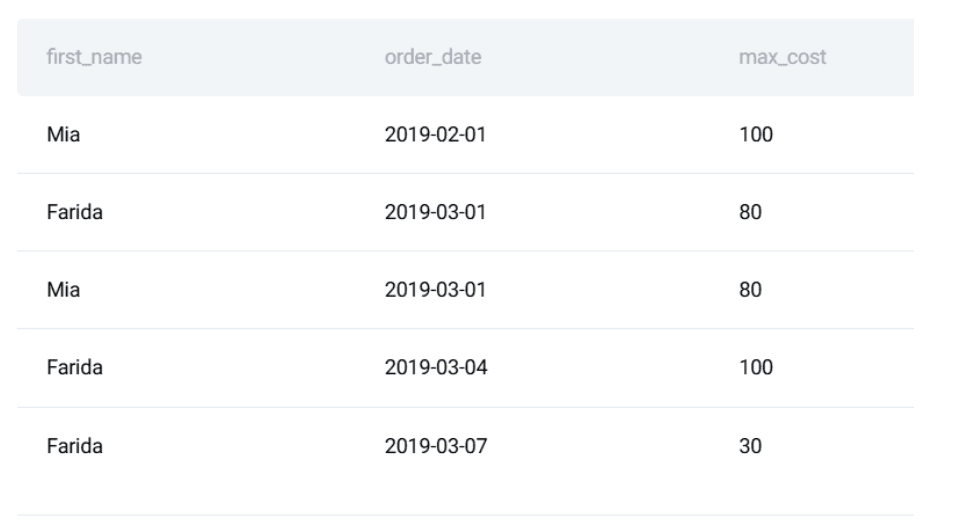
To illustrate the necessity of these advanced testing frameworks, consider a common business logic challenge frequently used in Amazon technical interviews. The objective is to identify customers with the highest daily total order cost within a specific date range. On the surface, the problem appears straightforward: join a customers table with an orders table, aggregate costs by day, and filter for the top spenders.
However, in a production environment at a scale like Amazon’s, the complexity is significant. The dataset involves two primary entities:
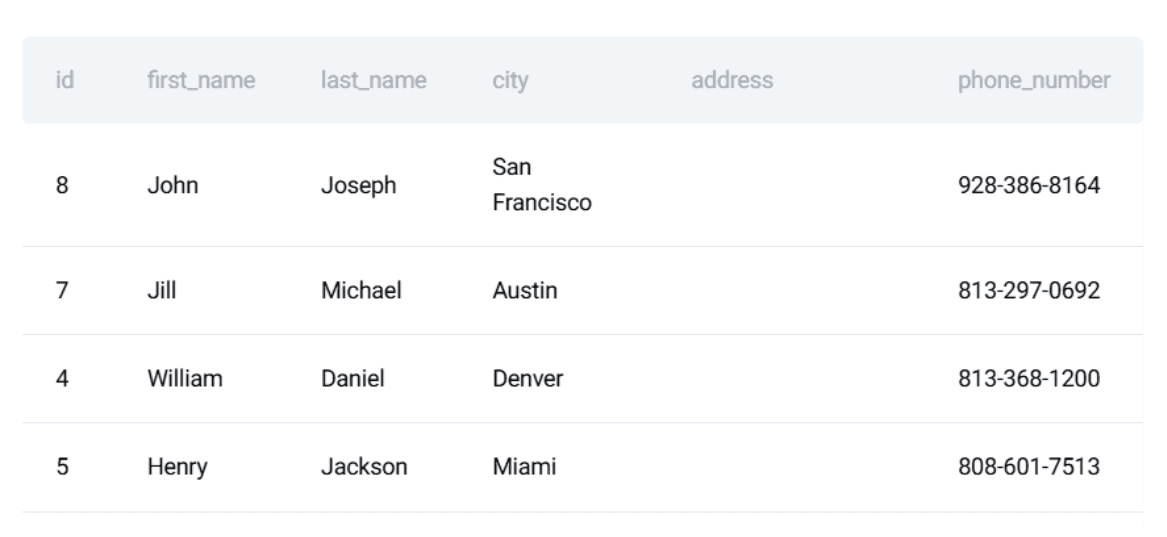
- The Customers Table: Containing unique identifiers, names, and demographic data.
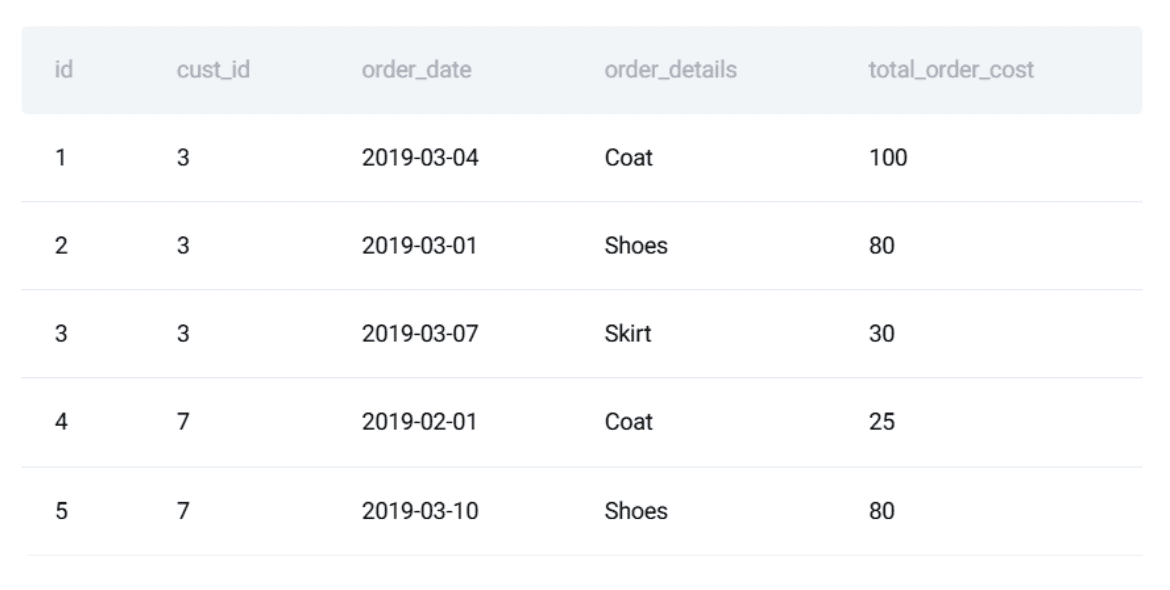
- The Orders Table: Tracking transaction IDs, customer links, order dates, and total costs.
The SQL solution requires sophisticated logic, utilizing Common Table Expressions (CTEs) and window functions. The process involves first calculating the total daily spend per customer, then ranking those customers within each specific date using the RANK() function, and finally filtering for those who hold the top position. While the logic is sound, it remains fragile. A change in how "order_date" is recorded or a duplicate customer ID could quietly corrupt the output, leading to incorrect high-value customer identification—a failure that could impact targeted marketing spend and customer relations.
Technical Implementation: SQL Unit Testing Frameworks
The first line of defense in a software-engineered SQL workflow is the unit test. Unlike manual spot-checks, unit tests provide a deterministic way to verify that logic remains consistent. The modern standard involves wrapping SQL queries within a Python-based testing suite, often utilizing the unittest or pytest libraries.

A critical component of this process is the use of in-memory databases, such as SQLite. By creating a temporary database in the system’s RAM, engineers can simulate a production environment without the overhead or cost of a full-scale cloud warehouse like Snowflake or BigQuery. This allows for:
- Isolation: Tests run in a clean environment, unaffected by other processes.
- Speed: In-memory execution provides near-instant feedback to the developer.
- Determinism: By inserting specific, controlled "dummy" data into the SQLite instance, the developer knows exactly what the output should be.
For the Amazon spender query, the test suite creates a mock customers and orders table, populates them with a handful of edge-case records (such as multiple orders on the same day or customers with no orders), and compares the query’s output against a pre-defined "expected" result. If the counts or the values differ by even a single digit, the test fails, alerting the engineer to a regression before the code ever reaches the production server.

Chronology of an Automated Data Workflow
The transition from a manual query to an automated, tested component follows a specific chronological path in a modern data stack:
- Code Definition: The engineer writes the SQL query, focusing on modularity and readability using CTEs.
- Test Integration: The query is integrated into a Python script. This script defines the "Ground Truth"—the input data and the expected output.
- Local Validation: The engineer runs the unit test locally. Any logic errors are caught and corrected in the development branch.
- Version Control Submission: The code is pushed to a repository (e.g., Git). This triggers a "Pull Request" (PR) process.
- Automated CI Execution: A CI/CD tool, such as GitHub Actions, detects the new code. It automatically spins up a virtual machine, installs the necessary dependencies (Pandas, SQLite), and executes the test suite.
- Approval or Rejection: If the tests pass, the code is eligible for merging. If they fail, the merge is blocked, preventing "broken" logic from entering the main codebase.
This chronology ensures that the production environment remains a "protected space," where only verified and tested logic is allowed to operate.
Supporting Data: The High Cost of Data Downtime
The push toward SQL testing is driven by the escalating cost of "data downtime"—periods where data is partial, erroneous, or missing. According to research from data observability firms, the average enterprise experiences dozens of data incidents per year, with the average cost of a single major data quality incident exceeding $100,000 in lost productivity and wasted resources.
Furthermore, Gartner reports that poor data quality is responsible for an average of $12.9 million in losses per year for organizations. By implementing automated SQL testing and CI/CD, companies are essentially purchasing insurance against these losses. The investment in writing tests upfront is significantly lower than the cost of remediating a corrupted database or making strategic business decisions based on faulty analytics.

Data Quality Automation: Beyond Logic Testing
While unit tests verify the logic of the SQL code, they do not necessarily verify the quality of the incoming data. In real-world environments, the data itself is often the source of failure. To address this, engineers are now integrating automated Data Quality (DQ) checks into their pipelines.
These checks act as "gatekeepers," verifying that the data meets specific criteria before it is processed. Common automated rules include:
- Uniqueness Checks: Ensuring that primary keys, such as Customer IDs, are not duplicated.
- Range Validations: Confirming that financial values (like order costs) are not negative and fall within realistic bounds.
- Referential Integrity: Ensuring that every order is linked to a valid customer who exists in the database.
- Temporal Checks: Verifying that order dates are not in the future and do not contain null values.
By wrapping these rules into a Python function that executes alongside the unit tests, engineers create a comprehensive safety net. If a data source begins sending malformed dates or duplicate records, the pipeline will "fail fast," halting execution and alerting the data team before the errors propagate to executive dashboards.
Industry Implications and Broader Impact
The adoption of software engineering principles for SQL marks a significant maturation of the data engineering field. It signals a move away from the "Wild West" era of ad-hoc data munging toward a disciplined, engineering-first approach.
This evolution has several profound implications for the industry:
- Role Convergence: The line between "Software Engineer" and "Data Engineer" is blurring. Modern data professionals are now expected to be proficient in Python, CI/CD, and testing frameworks, in addition to deep SQL expertise.
- Increased Trust: As data pipelines become more reliable, organizational trust in analytics grows. This enables more aggressive automation and the deployment of machine learning models that can operate autonomously.
- Scalability: Automated testing allows small data teams to manage massive, complex infrastructures. Without these safeguards, the "technical debt" of maintaining thousands of SQL queries would eventually overwhelm any human team.
In conclusion, treating SQL like software is no longer an optional "best practice" for elite tech companies; it is a fundamental requirement for any organization that views data as a strategic asset. By implementing unit testing, CI/CD, and automated data quality checks, the data community is building a more stable and trustworthy foundation for the future of digital intelligence. The Amazon case study serves as a reminder that even the simplest questions require a robust framework to ensure that the answers provided today remain correct tomorrow.








{kind=link}