

The transition of Large Language Models (LLMs) from experimental prototypes to robust production environments represents the most significant hurdle for enterprises in the current artificial intelligence era. While the barrier to entry for building AI-powered features has lowered significantly due to accessible APIs and open-source frameworks, the "deployment gap"—the space between a functioning local script and a reliable, scalable service—remains a complex challenge for software engineers and data scientists. Industry reports from 2024 indicate that while over 80% of enterprises have piloted generative AI projects, fewer than 20% have successfully moved these applications into full-scale production. This discrepancy highlights a fundamental misunderstanding of the deployment lifecycle, which requires a rigorous focus on architecture, cost-efficiency, safety, and continuous monitoring.
The Transition from Prototyping to Production
The initial excitement of building an LLM-powered feature often dissipates when the system encounters the volatility of real-world usage. In a controlled development environment, inputs are predictable, and latency is rarely a bottleneck. However, once a model is exposed to a diverse user base, several critical issues typically emerge: response times fluctuate, operational costs escalate exponentially with traffic, and the model may produce "hallucinations"—factually incorrect or nonsensical answers—that disrupt business workflows.
Mastering deployment is not merely a matter of hosting a model on a server; it is a multi-disciplinary effort that integrates software engineering best practices with the unique requirements of non-deterministic AI. To navigate this transition, organizations are increasingly adopting a structured seven-step methodology designed to ensure that LLM systems are not only innovative but also sustainable and safe.
Defining the Strategic Scope: Beyond the Generic Chatbot
The primary cause of failure in AI deployment is a lack of specificity. Many organizations begin with the vague objective of "building a chatbot," a goal that often leads to over-engineered systems that fail to meet user needs. Expert consensus suggests that the first step in a successful deployment is narrowing the use case to a specific, measurable task.

By defining whether a system is intended for FAQ automation, internal data retrieval, or structured data extraction, developers can tailor the underlying architecture accordingly. This specificity allows for the establishment of clear success metrics, such as task completion rates, response accuracy, and user satisfaction scores. For instance, a structured data extractor requires rigorous validation of JSON outputs, whereas a creative writing assistant prioritizes linguistic fluidity. Without these predefined boundaries, testing becomes impossible, and the system remains a "black box" that cannot be reliably optimized.
Model Selection and the Economics of Inference
Once the use case is established, the focus shifts to model selection. A common pitfall for engineering teams is the "maximalist approach"—defaulting to the largest, most powerful model available, such as GPT-4o or Claude 3.5 Sonnet. While these models offer high reasoning capabilities, they often introduce prohibitive latency and costs.
In a production environment, the "right" model is defined by a balance of three factors: accuracy, speed, and cost. For simple classification or summarization tasks, smaller, specialized models—or even distilled versions of larger models—often provide sufficient performance at a fraction of the cost. Furthermore, the decision between utilizing hosted APIs (such as OpenAI or Anthropic) versus deploying open-source models (such as Llama 3 or Mistral) on private infrastructure involves significant trade-offs. Hosted APIs offer ease of use and rapid scaling, whereas open-source models provide greater control over data privacy and long-term cost stability, albeit with higher operational overhead.
Architectural Integrity: The Rise of Modular LLM Pipelines
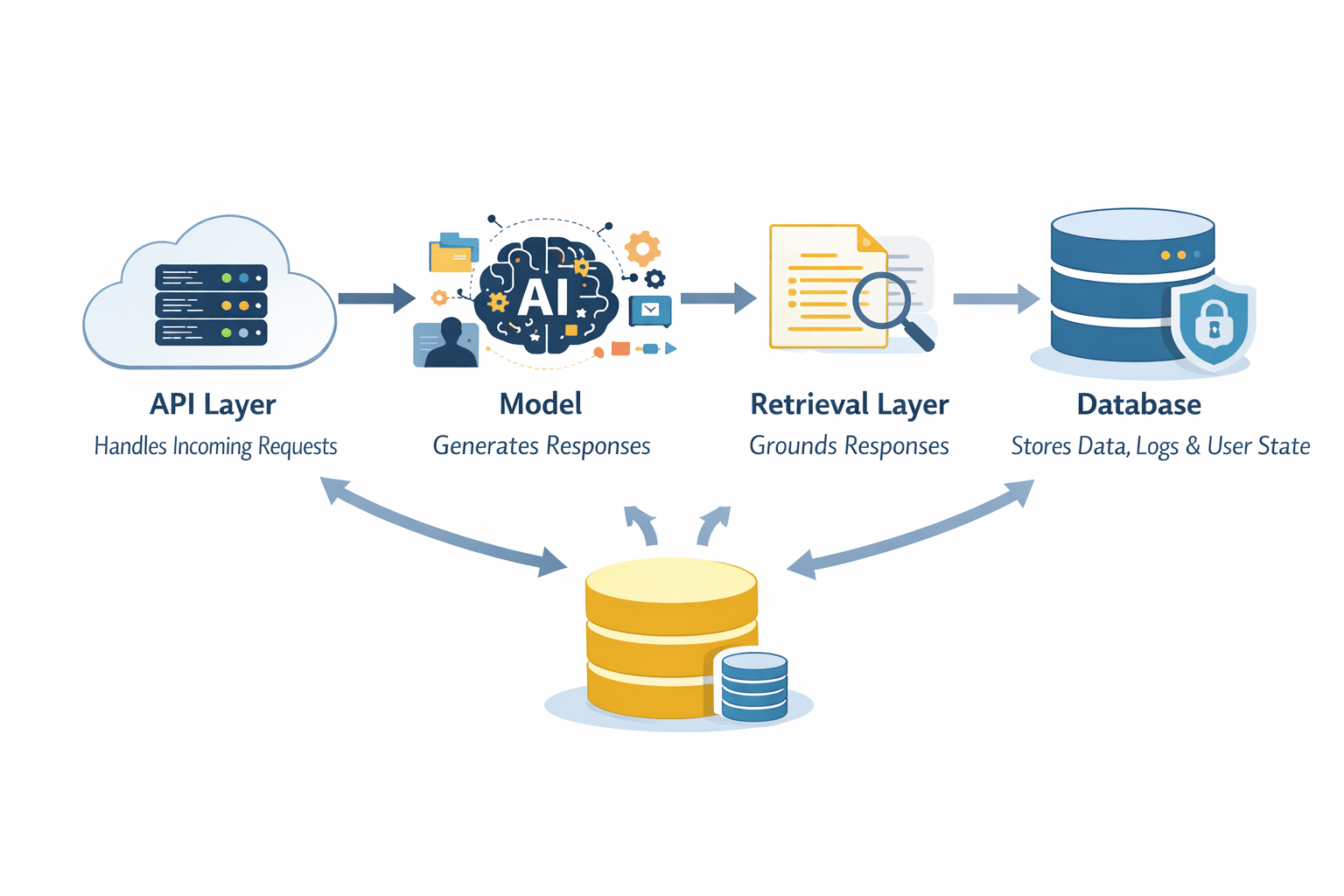
Modern LLM deployment has moved away from simple "input-output" loops toward complex, modular architectures. In these systems, the LLM is just one component of a larger pipeline. A standard production architecture typically includes:
- The API Layer: Manages authentication, rate limiting, and request routing.
- The Retrieval Layer: Often implemented as Retrieval-Augmented Generation (RAG), this layer fetches relevant context from external databases to ground the model’s responses in factual data.
- The Processing Layer: Handles prompt engineering, template management, and the actual model inference.
- The Storage Layer: Maintains conversation history, user state, and audit logs.
The industry is currently debating the merits of stateless versus stateful architectures. Stateless systems are inherently easier to scale and debug, but stateful systems are required for sophisticated multi-turn conversations. Engineers must carefully design these pipelines to ensure that each component is observable and that failures in one layer do not cause a total system collapse.
Implementation of Safety Protocols and Guardrails
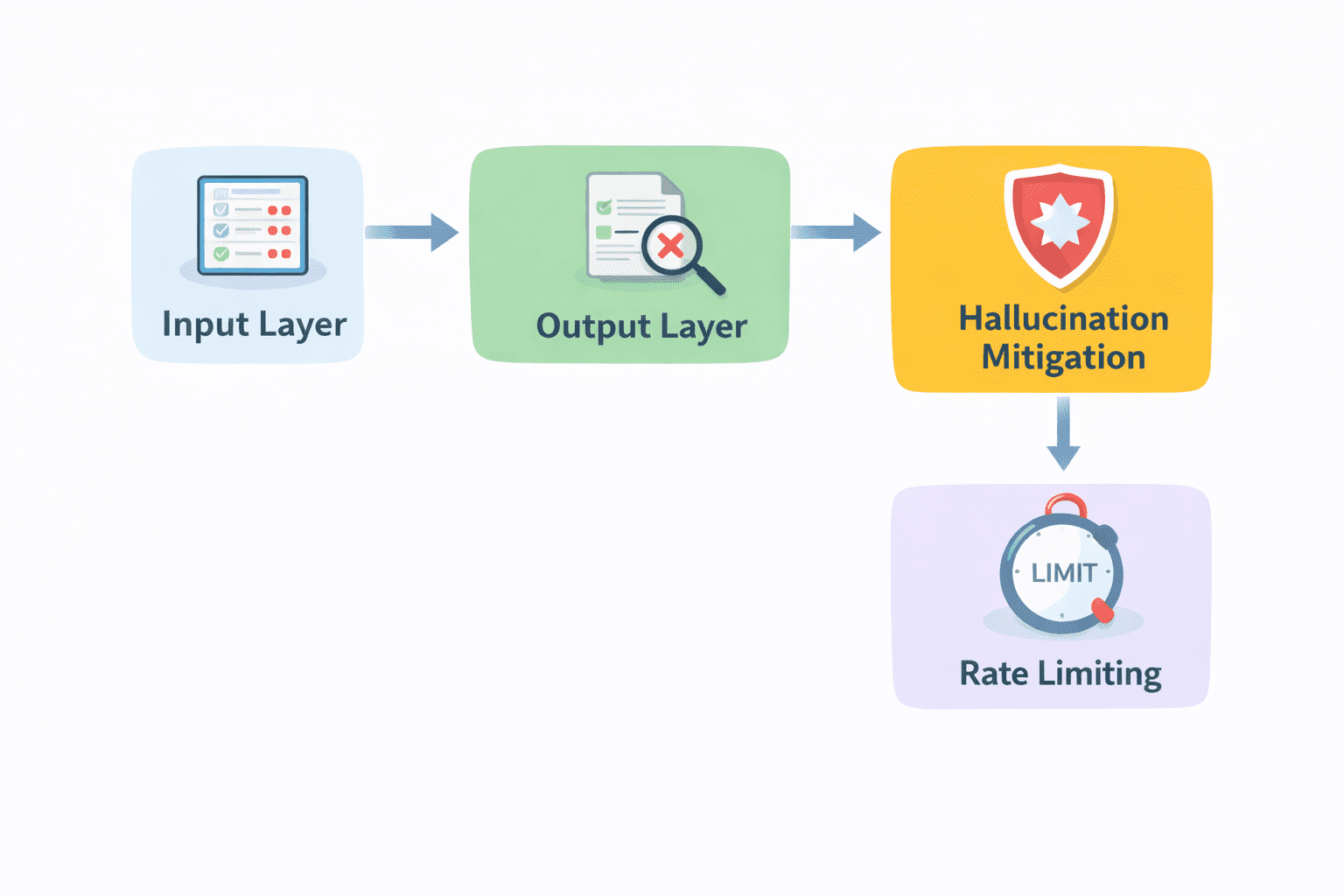
The non-deterministic nature of LLMs necessitates the implementation of safety layers, often referred to as "guardrails." Raw model output should rarely be presented to an end-user without intermediate validation. Guardrails serve multiple purposes: they prevent the disclosure of sensitive information (PII), filter out harmful or biased content, and ensure that the output adheres to a specific format.
Technical implementations of guardrails often involve "dual-model" setups, where a smaller, faster model acts as a supervisor, scanning the primary model’s output for violations before it is delivered. Organizations are also adopting "self-correction" loops, where the system detects an error in its own logic and re-runs the prompt with corrected instructions. These safety measures are critical for maintaining brand trust and complying with emerging global AI regulations, such as the EU AI Act.
Operational Efficiency: Balancing Latency and Scalability
Performance in AI systems is often measured by "Time to First Token" (TTFT) and total latency. In user-facing applications, delays of even a few seconds can lead to high churn rates. To combat this, deployment teams employ several optimization strategies:
- Semantic Caching: Storing responses to common queries in a vector database. If a new query is semantically similar to a cached one, the system returns the stored result instead of generating a new one, saving both time and money.
- Streaming: Delivering the response piece-by-piece as it is generated, which improves the "perceived speed" for the user.
- Dynamic Routing: Using a "router" model to send simple queries to cheap, fast models and complex queries to high-reasoning models.
- Batching: Processing multiple requests simultaneously to maximize GPU utilization and reduce per-request costs.
The Post-Deployment Lifecycle: Monitoring and Continuous Iteration
The deployment of an LLM is not a terminal event but the beginning of an iterative lifecycle. Unlike traditional software, AI models can suffer from "concept drift," where the relevance of their training data diminishes over time, or "model decay," where the system’s performance degrades as user behavior evolves.
Comprehensive monitoring requires tracking both technical metrics (latency, error rates, token usage) and qualitative metrics (helpfulness, accuracy, tone). Many teams now use "LLM-as-a-judge" frameworks, where a superior model evaluates the outputs of the production model based on a rubric. Furthermore, integrating user feedback—such as "thumbs up/down" buttons—provides the implicit data necessary for Reinforcement Learning from Human Feedback (RLHF) or prompt refinement.
Industry Chronology: The Evolution of LLM Deployment
The methodology for deploying LLMs has evolved rapidly over the past 24 months:
- Late 2022 – Early 2023: The "Wrapper Era." Most deployments were simple interfaces around the GPT-3.5 API with minimal logic.
- Mid 2023: The "RAG Revolution." The industry shifted toward grounding models in private data using vector databases to solve the hallucination problem.
- Early 2024: The "LLMOps Expansion." Focus shifted toward fine-tuning, evaluation frameworks, and safety guardrails as enterprises sought to move beyond simple pilots.
- Present: The "Agentic Workflow" phase. Deployment now involves complex multi-agent systems where LLMs use tools, call APIs, and perform autonomous tasks.
Supporting Data and Technical Benchmarks
Data from recent infrastructure surveys indicates the following trends in the LLM landscape:
- Cost Management: Enterprises using dynamic routing and caching report up to a 60% reduction in monthly inference costs compared to those using static, large-model architectures.
- Latency Expectations: User experience research suggests that for interactive applications, a TTFT of under 200ms is required to maintain a "conversational" feel.
- Error Rates: Without RAG or guardrails, LLM hallucination rates in technical domains can be as high as 15-20%. With optimized retrieval and validation, this can be reduced to less than 2%.
Expert Perspectives and Market Implications
The move toward standardized deployment steps reflects a maturing industry. Technical analysts suggest that the ability to deploy LLMs reliably will soon be a "table stakes" requirement for any technology company. Shittu Olumide, a software engineer and technical writer, emphasizes that the most successful deployments are those that prioritize reliability over "flashy" features.
The broader impact of these deployment strategies is a shift in the labor market, with increasing demand for "AI Engineers" who possess a blend of traditional DevOps skills and specialized knowledge in model orchestration. As these seven steps become industry standards, the focus of AI development will likely shift from "how do we build this?" to "how do we maintain and improve this at scale?" This transition marks the end of the experimental phase of generative AI and the beginning of its integration into the bedrock of global digital infrastructure.








{kind=link}