Dealing with Duplicate Content Rel Canonical & Google SEO
Dealing with duplicate content rel canonical style google seo – Dealing with duplicate content rel canonical style google is crucial for any website aiming for high search engine rankings. This comprehensive guide delves into understanding the various types of duplicate content, from identical copies to near-duplicates and thin content, exploring their detrimental effects on . We’ll also uncover the vital role of the rel=”canonical” tag in guiding search engines toward the correct version of a page.
Furthermore, we’ll analyze Google’s perspective on duplicate content, providing insights into their algorithms and strategies. Finally, practical strategies for preventing duplicate content creation and handling existing issues on websites, including advanced scenarios like internationalization, will be covered.
This in-depth exploration will equip you with the knowledge and tools to optimize your website for better search engine visibility and avoid the penalties associated with duplicate content. We’ll cover everything from content strategies to technical considerations and the use of valuable tools for analysis. Learn how to identify, remove, and update duplicate content, and implement the rel=”canonical” tag effectively.
This will help your website rank higher and improve your overall online presence.
Understanding Duplicate Content
Duplicate content is a significant concern, as search engines aim to provide unique and valuable information to users. Websites with substantial duplicate content risk lower search engine rankings and decreased organic traffic. Understanding the various forms and causes of duplicate content is crucial for maintaining a healthy online presence and achieving optimal performance.Duplicate content, in its simplest form, is the presentation of identical or near-identical text across multiple pages on a website or on different websites.
This redundancy can confuse search engines, potentially leading them to penalize the affected pages. This is because search engines prioritize original, unique content, and duplicate content can be perceived as spam or an attempt to manipulate search rankings.
Dealing with duplicate content is crucial for SEO, and using the rel canonical tag is key. High-end brands often need sophisticated social media strategies, and agencies like advance social media management agencies for luxury brands can help navigate that complex landscape. Ultimately, a strong SEO strategy, including proper canonical tags, is still essential for any brand, regardless of its industry or size.
Definition of Duplicate Content
Duplicate content encompasses any instance where substantial portions of text are repeated on a website or across multiple sites. This includes identical copies, near-duplicates, and instances of thin content. The impact on search engine optimization is a direct consequence of search engines’ desire to provide unique, valuable content to users. Duplicate content signals to search engines that the website lacks originality and depth, potentially diminishing the website’s authority and ranking.
Types of Duplicate Content
Duplicate content manifests in various forms. Identical content refers to word-for-word duplication of content across multiple pages. Near-duplicate content involves slight variations in phrasing or sentence structure, but the core message remains largely the same. Thin content, characterized by superficial or minimal content, is another form. Thin content often lacks depth, fails to provide substantial value, and can result in poor rankings.
Scenarios Leading to Duplicate Content
Duplicate content can arise from various website practices and circumstances. Dynamically generated content, if not handled carefully, can produce multiple pages with similar text. Mirrored websites, where identical or near-identical content is replicated across domains, are another source. Content scraping, where text from other websites is copied without permission, is also a significant contributor to duplicate content issues.
Finally, poor content management systems (CMS) configurations or outdated templates can sometimes inadvertently generate duplicate content.
Examples of Duplicate Content
Consider a website selling athletic shoes. Identical product descriptions on multiple product pages are an example of identical content. Near-duplicate content might involve slightly different descriptions of the same shoe model, but with identical information. Thin content might involve a product page with only a short, generic description and no detailed features. This demonstrates the varying levels of similarity in duplicate content.
Negative Consequences of Duplicate Content on Ranking
| Type of Duplicate Content | Impact on Ranking |
|---|---|
| Identical Content | Significant ranking penalties, potential removal from search results |
| Near-Duplicate Content | Lower rankings, reduced visibility |
| Thin Content | Low rankings, poor user experience signals |
Duplicate content can lead to a range of negative impacts on search engine rankings, affecting the visibility and discoverability of a website. Identical content can result in severe penalties, potentially even removal from search results. Near-duplicate content negatively impacts ranking and visibility, while thin content signals poor user experience, leading to lower rankings.
The Role of rel=”canonical”
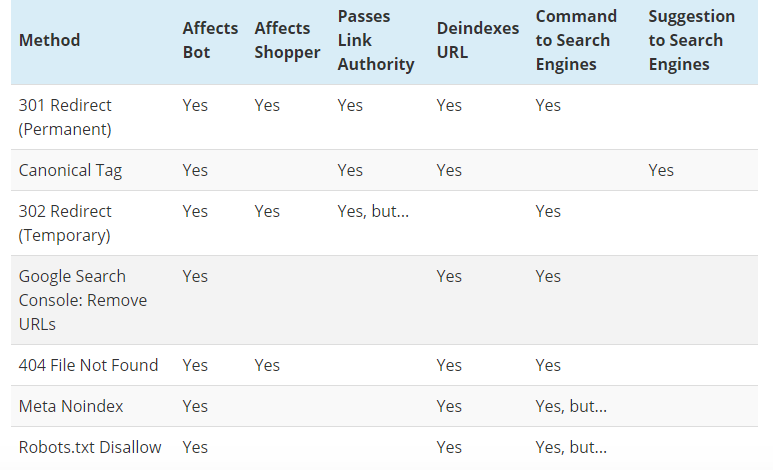
The internet is a vast network of interconnected pages. Duplicate content, whether intentional or accidental, can negatively impact search engine rankings. This is where the `rel=”canonical”` tag plays a crucial role. This tag signals to search engines which version of a page is the primary one, helping to avoid issues with duplicate content penalties.The `rel=”canonical”` tag is an HTML attribute that helps search engines understand the hierarchical structure of a website and the preferred version of a page.
This is essential for managing duplicate content and ensuring search engines crawl and index the correct version of a page, ultimately improving the site’s visibility and search ranking.
Dealing with duplicate content using the rel canonical tag is crucial for Google SEO. If your site isn’t ranking as high as you’d like, it could be a sign that Google is having trouble differentiating between similar pages. One of the common causes is a lack of proper canonicalization. This is where the rel canonical tag comes in handy.
Properly implementing this tag helps Google understand which version of a page is the authoritative one, avoiding issues like duplicate content penalties and ultimately helping your site rank better in search results. You can learn more about the common reasons behind poor rankings in this helpful guide: why isnt my website ranking. Making sure you’ve implemented the rel canonical tag correctly is an important step in fixing this potential problem.
Purpose and Function
The `rel=”canonical”` tag’s primary function is to declare a specific URL as the standard or preferred version of a page when multiple URLs exist with similar or identical content. By using this tag, webmasters indicate to search engines which URL they consider the authoritative source. Search engines then prioritize indexing and ranking the canonical URL, thus avoiding confusion and potential penalties for duplicate content.
How rel=”canonical” Helps Search Engines
The `rel=”canonical”` tag helps search engines understand the primary version of a page by directing them to the intended source. This ensures that search results accurately reflect the content and avoids the dilution of search engine ranking signals. This accurate representation of the content is crucial for a positive user experience, as search results will be more focused and relevant.
Correct Implementation
The `rel=”canonical”` tag is placed within the `
` section of the HTML document. It’s typically placed within the `` tag. A correct implementation points to the primary URL of the page. Incorrect implementations can lead to issues with indexing and ranking.- Place the tag within the `` section of the HTML document.
- Ensure the `href` attribute points to the correct canonical URL.
- Use the correct syntax: ``
Examples of Correct and Incorrect Implementation
- Correct Implementation: ` ` This example correctly points to the canonical URL for a product detail page.
- Incorrect Implementation (missing attribute): ` ` This example is missing the `href` attribute, making it invalid.
- Incorrect Implementation (wrong URL): ` ` This example points to a different website, which is not appropriate.
Impact Comparison Table
| Feature | Using rel=”canonical” | Not Using rel=”canonical” |
|---|---|---|
| Search Engine Understanding | Search engines understand the primary page, improving indexing and ranking. | Search engines may index multiple versions, leading to diluted signals and potential ranking issues. |
| Duplicate Content Issues | Helps prevent duplicate content penalties, maintaining a healthy website profile. | Potential for duplicate content penalties, harming search engine rankings. |
| Crawling Efficiency | Search engines prioritize the canonical URL, optimizing crawling efficiency. | Search engines may crawl multiple versions, wasting resources and potentially impacting indexing speed. |
| User Experience | Provides a consistent and accurate representation of the content to users. | Users might encounter different versions of the same content, which can confuse them. |
Google’s Perspective on Duplicate Content
Understanding how Google views duplicate content is crucial for maintaining a healthy website. Duplicate content, whether intentional or accidental, can significantly impact a site’s search engine rankings. Google’s algorithms are designed to identify and address this issue, often penalizing sites that fail to comply with their guidelines. This section dives deep into Google’s approach to duplicate content, including their strategies, guidelines, and potential penalties.Google’s approach to duplicate content involves sophisticated algorithms that analyze website content for similarities across different pages.
These algorithms are constantly evolving, making it imperative for website owners to stay updated on best practices. Google’s goal is to provide users with the most relevant and unique content, and duplicate content can interfere with this goal.
Google’s Duplicate Content Algorithms
Google employs complex algorithms to identify and assess duplicate content. These algorithms consider various factors, including the extent of similarity, the context surrounding the duplicate content, and the overall quality of the website. Sophisticated pattern recognition techniques and machine learning models are used to identify patterns and inconsistencies in content. The evaluation also takes into account the intent and purpose of the content.
Google’s Guidelines for Avoiding Duplicate Content
Creating unique and original content is paramount. Google prioritizes content that is valuable and provides a unique perspective. Following these guidelines helps maintain a positive relationship with Google’s search algorithms. Creating unique content for each page and avoiding mirroring content from other sites are fundamental aspects of this.
- Create original content that offers value to users.
- Avoid copying content from other websites. Use your own research and ideas.
- Ensure each page has a distinct purpose and focus.
- Use proper research and target unique search queries.
- Implement proper canonicalization to indicate the preferred version of similar content.
Examples of Penalties for Duplicate Content Violations
Violating Google’s guidelines on duplicate content can result in penalties ranging from minor ranking adjustments to complete removal from search results. The severity of the penalty often depends on the extent of the violation and the overall quality of the website.
- Lower search rankings: Websites with significant duplicate content often see their search rankings drop, making it harder for users to find their site.
- Reduced visibility: Sites with repeated instances of duplicate content might see their overall visibility reduced in search results.
- Removal from search results: In severe cases of intentional and widespread duplicate content, Google may completely remove the site from search results.
Google’s Preferred Methods for Managing Multiple Versions of Similar Content
When multiple versions of similar content exist, Google prefers a clear and consistent approach to indicate the preferred version. This helps avoid confusion for both users and search engines. Implementing the `rel=”canonical”` attribute is a vital part of this.
- Using the `rel=”canonical”` attribute: This attribute clearly identifies the preferred version of a page, which is crucial when dealing with multiple versions of similar content. This is vital for preventing Google from treating the duplicates as separate pages.
- Creating distinct content: For each piece of content, strive for originality. Ensure that each page has a unique focus, value proposition, and target audience.
- Content diversification: Adding unique elements like images, videos, or interactive components can enhance the value and distinctiveness of content.
Common Google Penalties for Duplicate Content Issues
This table Artikels potential penalties for various duplicate content issues. The severity of the penalty depends on the nature and extent of the duplication.
| Duplicate Content Issue | Potential Penalty |
|---|---|
| Exact duplication of content across multiple pages | Significant ranking drop |
| Minor variations of existing content | Moderate ranking drop |
| Large-scale content mirroring from other sites | Possible site removal from search results |
| Non-canonical links pointing to duplicate content | Reduced visibility in search results |
Content Strategies for Avoiding Duplication
Duplicate content is a significant concern, hindering search engine rankings and potentially harming your website’s reputation. Effective content strategies are crucial for creating unique, high-quality content that not only avoids penalties but also attracts and retains a targeted audience. This section delves into various strategies for preventing duplicate content, focusing on originality, best practices, and optimizing existing content.Implementing these strategies will lead to a more successful campaign and a higher quality user experience.
A website with unique and engaging content will attract more visitors and maintain their interest.
Dealing with duplicate content is a real SEO headache, and using the rel canonical tag is key for Google. Understanding how to correctly implement these tags is crucial for ranking. When explaining this to your boss, you can emphasize that it’s a critical part of maintaining a healthy website, and highlight the impact on search visibility. For example, you might mention the importance of clean, well-structured code for the user experience and how that ties back into Google’s algorithm.
Check out this helpful guide on how to explain SEO to your boss how to explain seo to your boss for some practical tips. Ultimately, using rel canonical effectively ensures search engines don’t get confused by duplicate content, which ultimately improves your site’s rankings.
Unique and Original Content Creation, Dealing with duplicate content rel canonical style google seo
Creating unique content is the cornerstone of effective . Simply replicating existing content, even with slight modifications, is detrimental. Google’s algorithms are sophisticated enough to detect and penalize such practices. The key is to generate original ideas, perspectives, and information that are genuinely valuable to your target audience. This involves thorough research, in-depth analysis, and a focus on providing fresh insights.
Best Practices for Content Creation and Publishing
Following best practices during content creation and publishing is vital for avoiding duplicate content issues. These practices ensure that each piece of content is distinct and optimized for search engines. This involves meticulous attention to detail in every stage of the process.
- Thorough Research: Comprehensive research is paramount. Investigate topics deeply, consult reliable sources, and gather diverse perspectives to ensure the content is accurate, insightful, and original. Conduct research to understand what your target audience is searching for and incorporate those terms naturally.
- Unique Writing Style: Develop a distinctive writing style that reflects your brand’s voice and resonates with your target audience. Avoid mimicking other content creators. Focus on crafting engaging and informative content that keeps readers interested.
- In-Depth Analysis: Analyze the topic from multiple angles. Explore various perspectives and provide comprehensive coverage to create unique and valuable content. This will differentiate your content from similar articles.
Optimizing Existing Content
If you already have content that may be duplicated or needs improvement, strategic optimization can help. The goal is to make each piece of content unique and valuable without compromising its original intent.
- Review and Update: Regularly review existing content to identify areas needing updates or revisions. Ensure accuracy, relevance, and clarity. Incorporate new information and research findings to maintain the content’s value.
- Rephrasing and Rewriting: Rephrase existing content to make it more unique and original. Rewrite sentences and paragraphs to convey the same information in a different way. Focus on clarity and conciseness.
- Adding Unique Elements: Enhance existing content with new elements such as visuals, data visualizations, infographics, and interactive content. These additions will make your content more appealing and informative, making it stand out from other sources.
Content Quality Guidelines
High-quality content is crucial for both and user engagement. The following guidelines ensure your content stands out and avoids duplication issues.
- Accuracy and Reliability: Verify all information presented and ensure it’s accurate and comes from credible sources. Incorrect or outdated information can damage your credibility and hurt your efforts.
- Clarity and Conciseness: Write clearly and concisely, avoiding jargon or overly complex language. Ensure your content is easy to understand and digest for your target audience.
- Originality and Uniqueness: Strive for originality in every piece of content. Avoid plagiarism and create content that reflects your unique perspective and voice.
- Relevance and Value: Ensure your content is relevant to your target audience and provides genuine value. Focus on answering their questions and addressing their needs.
Handling Duplicate Content on Existing Websites
Dealing with duplicate content on an existing website requires a systematic approach. Ignoring duplicate content can severely impact your search engine rankings and user experience. This section provides practical strategies for identifying, analyzing, removing, updating, and implementing canonical tags to resolve duplicate content issues effectively.Identifying and analyzing duplicate content is crucial for effective remediation. A thorough audit helps pinpoint instances of identical or near-identical content across different pages, often a result of unintentional mirroring, dynamic content generation, or poor content management practices.
Duplicate Content Identification Strategies
Analyzing existing website content for duplication requires a multi-faceted approach. Tools and techniques can pinpoint instances of redundant material, including using specialized software and conducting manual reviews.
- Automated Tools: Utilize tools or web crawlers to scan your website for duplicate content. These tools often highlight pages with similar text, URLs, and meta descriptions, helping you quickly identify potential issues. Some tools offer the ability to compare content across different pages and provide detailed reports.
- Manual Reviews: Thoroughly examine pages for similar content by reading through the content of various pages on your website. This includes comparing product descriptions, blog posts, and articles to find exact or near-duplicate content. Manual reviews provide insights into the root causes of duplication, enabling targeted solutions.
- Content Similarity Analysis: Employ advanced tools or techniques to analyze the similarity of content across pages. This involves using algorithms to compare text, images, and other content elements. This approach helps determine if there’s more than just a few overlapping words.
Duplicate Content Removal or Update Procedures
Once duplicates are identified, implementing a strategy to address them is necessary. This involves either removing the duplicate content or updating it to ensure uniqueness.
- Content Removal: If a duplicate page is identical or very similar to another, consider removing the less valuable or relevant page. Prioritize pages with strong backlinks or those providing a unique perspective. Redirect the duplicate page to the original, more relevant page using 301 redirects.
- Content Update: If the duplicate content is slightly different, update the content to ensure originality. This may involve rewriting sections, adding new information, or incorporating fresh perspectives. Updating existing content is often more effective than removing it entirely.
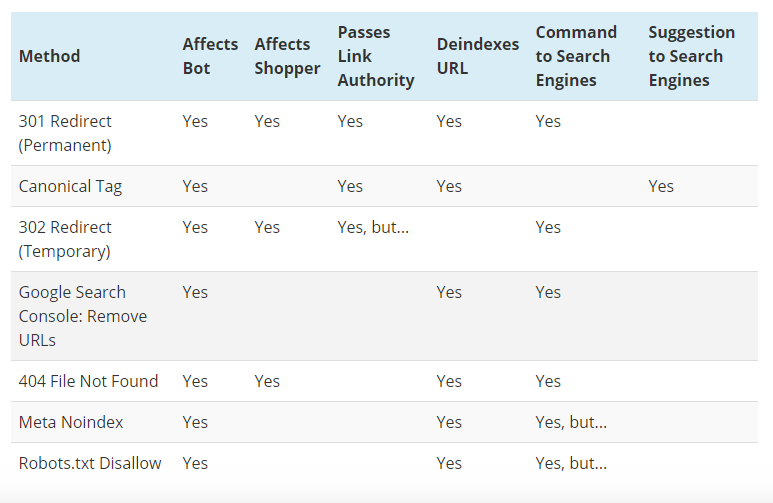
Implementing rel=”canonical” Tags
Using rel=”canonical” tags is an essential part of duplicate content resolution. It helps search engines understand which version of a page is the authoritative one.
- Identifying Canonical URLs: Determine which version of each duplicated page is the most authoritative. Consider factors such as the page’s content quality, backlinks, and overall relevance. Select the most comprehensive and valuable version as the canonical.
- Adding Canonical Tags: Add the rel=”canonical” tag to the duplicate pages pointing to the chosen canonical URL. This ensures search engines prioritize the correct version. Implement this tag within the ` ` section of the duplicate page’s HTML.
- Example:
<link rel="canonical" href="https://www.example.com/original-page" />
The code above places the canonical tag, directing search engines to the original URL.
Content Audit Importance
A robust content audit is crucial for identifying and addressing duplicate content issues. It provides a comprehensive overview of your website’s content, allowing you to optimize it for better search engine rankings and user experience.
- Comprehensive Assessment: A thorough content audit analyzes all website pages, examining content quality, relevance, and structure. It includes checking for duplicated content and identifying areas that need improvement.
- Prioritization: Content audits prioritize addressing the most significant duplicate content issues. This often involves focusing on pages with high traffic or strong backlinks, which are more likely to negatively impact your search rankings.
- Long-term Strategy: Content audits are an ongoing process. By regularly auditing your website, you can prevent future duplicate content issues and maintain high search engine rankings.
Step-by-Step Guide for Fixing Duplicate Content
A systematic approach to fixing duplicate content issues is crucial. This includes the steps for identifying duplicates, updating or removing them, and implementing canonical tags.
- Identify Duplicates: Use tools and manual reviews to identify duplicate content on your website. This involves comparing pages and analyzing their content for similarities.
- Choose Canonical URLs: Select the authoritative version of each duplicated page. This is the page that should be considered the main source of information.
- Implement rel=”canonical” Tags: Add rel=”canonical” tags to all duplicate pages, linking them to their respective canonical URL.
- Update or Remove Content: Update or remove duplicate content, as appropriate. Redirect duplicate pages to the canonical URL to maintain user experience.
- Monitor Results: Track changes in search engine rankings and website traffic to ensure your efforts are effective.
Advanced Duplicate Content Issues
Dealing with duplicate content isn’t always straightforward, especially when dealing with complex website structures. This section dives deeper into specific scenarios where duplicate content challenges can arise, such as internationalization, multiple domains, e-commerce platforms, and large-scale websites. Understanding these advanced issues is crucial for implementing effective strategies and maintaining a positive user experience.
Addressing duplicate content across different versions of a website, whether for different languages or regions, requires careful consideration. Failing to manage this effectively can lead to significant ranking penalties from search engines. The focus shifts from just identifying the duplicates to actively managing and directing users to the correct version.
Internationalization and Multi-lingual Websites
Internationalized websites often present a significant challenge. Each language version represents a potential source of duplicate content if not carefully managed. Strategies for handling this include using hreflang tags to signal the appropriate language version to search engines, separating content based on language in a structured manner, and utilizing a content management system (CMS) that supports multilingual content.
Duplicate Content Across Different Domains or Subdomains
Duplicate content can also arise from multiple domains or subdomains pointing to the same or very similar content. This is a common issue in companies with multiple branches or online stores. Redirecting or using canonical tags to specify the primary source is vital to avoid search engine penalties. The canonical tag should point to the primary domain or subdomain where the content should be indexed.
Duplicate Content Issues in E-commerce Settings
E-commerce sites are particularly vulnerable to duplicate content issues. Variations in product listings, different product views (e.g., standard, large, zoom), and automated generated content (such as “similar products”) can create duplicates. Implementing structured data markup for product information and utilizing canonical tags for different variations are essential for directing search engines to the correct and authoritative versions.
Managing Duplicate Content on Large Websites
Large websites often contain a vast amount of content, increasing the likelihood of duplicate content. Systematic content audits, utilizing tools to identify duplicates, and employing a robust content management system (CMS) that prevents the creation of duplicate content are crucial. Additionally, a well-defined content strategy that avoids redundant content creation will minimize future duplicate content problems. Regular reviews of existing content to ensure it is still relevant and valuable are also recommended.
Managing Duplicate Content in Specific Niche Websites
Specific niche websites, such as those covering a very specialized topic, can face duplicate content issues from syndicated content or articles that appear on other sites. Utilizing canonical tags to point to the original source and avoiding redundant content creation are essential for these types of websites.
Technical Considerations: Dealing With Duplicate Content Rel Canonical Style Google Seo
Preventing duplicate content isn’t just about writing unique copy; it’s a multifaceted technical challenge. Proper technical implementation is crucial to ensuring search engines understand and index your content accurately, avoiding penalties and maximizing visibility. This involves careful attention to URL structures, robots.txt directives, and sitemaps.
Technical plays a critical role in mitigating duplicate content issues. By optimizing the technical aspects of your website, you can help search engines understand your content better, leading to improved rankings and user experience. This section delves into the practical steps for implementing these strategies.
URL Structures and Parameter Management
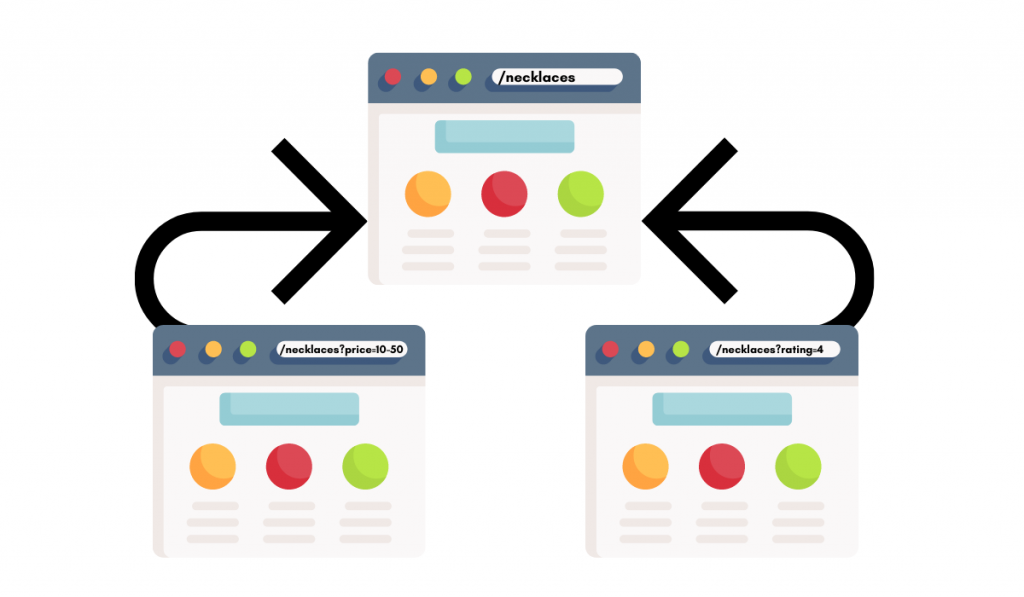
Proper URL structures are fundamental for avoiding duplicate content. Search engines interpret different URLs as different pieces of content, which can lead to issues if not handled correctly. Using descriptive, -rich URLs that clearly reflect the page’s content is crucial.
Avoid using unnecessary parameters in URLs. These parameters, often appended to URLs, can create multiple URLs that represent the same content. For instance, a URL like “product.html?color=red” and “product.html?size=large” might represent the same product, but as separate pages to the search engine. Removing or properly handling these parameters is essential to avoid duplication.
Robots.txt for Crawl Prevention
Robots.txt is a crucial tool for controlling how search engine crawlers interact with your website. It’s important to use it effectively to prevent duplicate content issues that arise from unnecessary crawling.
By strategically defining which parts of your site are accessible to crawlers, you can prevent them from indexing redundant or duplicate content. This ensures that search engines focus their efforts on unique and valuable content, thus reducing the risk of duplicate content penalties.
Sitemaps for Content Management
Sitemaps provide a structured overview of your website’s content to search engine crawlers. Well-structured sitemaps are vital for ensuring that all essential pages are correctly indexed.
Use sitemaps to highlight unique content and avoid submitting duplicate versions. By properly organizing and presenting your site’s structure, you can guide search engines to the most important pages, preventing them from indexing duplicate content. Consider submitting different sitemaps for different content types to better manage your site’s overall indexing.
Technical Flowchart for Duplicate Content Prevention
| Step | Action | Description |
|---|---|---|
| 1 | Analyze Existing URLs | Identify and categorize URLs that might be duplicates. Use tools to find potential issues. |
| 2 | Implement rel=”canonical” | Use the rel=”canonical” tag to specify the primary version of each piece of content. |
| 3 | Optimize URL Structures | Create clear, descriptive, and -rich URLs that avoid unnecessary parameters. |
| 4 | Review robots.txt | Ensure robots.txt correctly directs crawlers to avoid crawling duplicate content or pages with low value. |
| 5 | Update Sitemaps | Update sitemaps to reflect changes and ensure unique content is prioritized. |
| 6 | Monitor and Evaluate | Track the results of implemented changes, using search console and other tools. Regularly check for new duplicate content issues. |
Tools and Resources for Duplicate Content Analysis
Unveiling hidden duplicates in your website’s content is crucial for success. Duplicate content, whether intentional or unintentional, can severely harm your search engine rankings. Identifying and addressing these issues proactively is key to maintaining a healthy online presence. Tools designed for duplicate content analysis can automate this process, helping you pinpoint areas needing attention.
Effective duplicate content analysis is not just about finding identical copies; it’s about recognizing near-duplicates and paraphrased content that search engines might perceive as similar. By understanding the nuances of duplicate content detection, you can make informed decisions about your content strategy and optimize your site for better visibility and ranking.
Duplicate Content Detection Tools
Numerous tools are available to assist in identifying duplicate content issues. These tools vary in features, pricing, and complexity, so understanding their capabilities is vital for choosing the right one for your needs. A crucial step is to understand the functionalities of these tools to make the most informed choice.
Key Functionalities of Duplicate Content Analysis Tools
These tools typically offer functionalities for:
- Content Comparison: Tools compare your website’s content against itself and external sources. They often utilize sophisticated algorithms to identify near-duplicates, paraphrased text, and identical content across different pages or external websites. This allows you to pinpoint sections of your website that may be identical or overly similar to other content.
- Analysis: Tools analyze usage and density across your site. This helps you understand content overlap and areas where your s might be overused or inappropriately distributed. This assists in creating content that uses s effectively without becoming overly repetitive.
- Backlink Analysis: Some tools also analyze backlinks to identify potential duplicate content issues originating from other websites. This is especially useful in detecting if your content is being reproduced elsewhere without proper attribution or if it’s linked to similar content on other sites. It allows for a broader perspective, extending beyond just the content on your website.
- Reporting and Visualization: Tools typically provide detailed reports, often with visual representations like charts and tables, highlighting the identified duplicate content. These reports help you understand the extent of the issue and focus your efforts on specific areas.
Popular Duplicate Content Detection Tools Comparison
A comparison of popular tools can assist in selecting the most suitable option for your specific needs.
| Tool | Functionality | Pricing | Ease of Use |
|---|---|---|---|
| Copyscape | Comprehensive content comparison, backlink analysis, and reporting. | Subscription-based | Generally user-friendly |
| Siteliner | Free and comprehensive analysis of your site’s content for duplicates, including internal and external comparisons. | Free version with limitations, paid versions available | User-friendly interface, especially for basic needs. |
| Plagiarism Checker | Specific for detecting plagiarism, including paraphrasing and rewriting. | Subscription-based | Ease of use depends on the specific tool. |
| SimilarWeb | Provides insights into competitors’ content and potential overlap, helping to identify similar content. | Subscription-based | User-friendly interface for data analysis. |
Regular Auditing for Duplicate Content
Regular content audits are essential for maintaining a healthy website. This involves periodic checks for duplicate content, ensuring that your content remains unique and well-optimized for search engines. These audits are not a one-time activity but a continuous process for maintaining a healthy online presence.
Conclusive Thoughts
In conclusion, effectively managing duplicate content is essential for a successful strategy. By understanding the different types of duplicate content, the role of rel=”canonical,” Google’s approach, and implementing preventative strategies, you can significantly improve your website’s search engine ranking. This guide provides a thorough understanding of the subject, covering everything from basic principles to advanced issues and technical considerations.
By addressing duplicate content proactively, you’ll position your website for long-term success and avoid potential penalties.