Robots TXT Marketing Explained SEO Strategies
Robots TXT marketing explained is crucial for website visibility. This guide dives deep into how a simple text file can dramatically impact your strategy. We’ll explore everything from the basics of robots.txt to advanced techniques and best practices, including how to use it for mobile optimization. Get ready to unlock the power of this often-overlooked tool.
Understanding how robots.txt works is fundamental for any website owner or marketer. This file acts as a guide for search engine crawlers, instructing them on which parts of your site to index and which to ignore. This can directly affect your website’s visibility in search results, and consequently, your organic traffic.
Introduction to Robots.txt
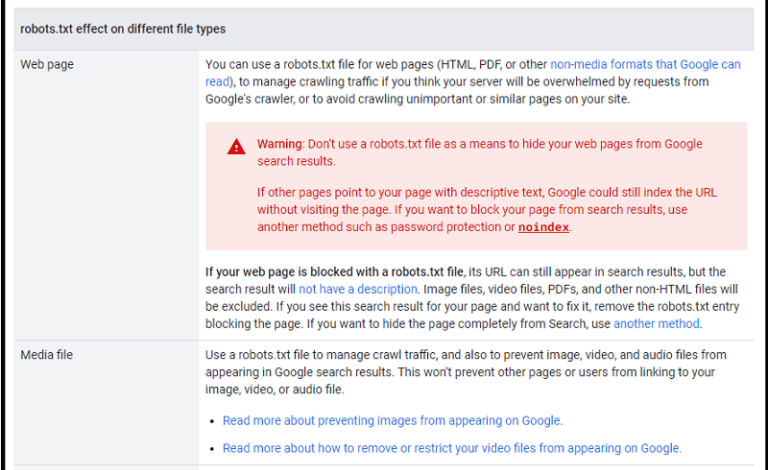
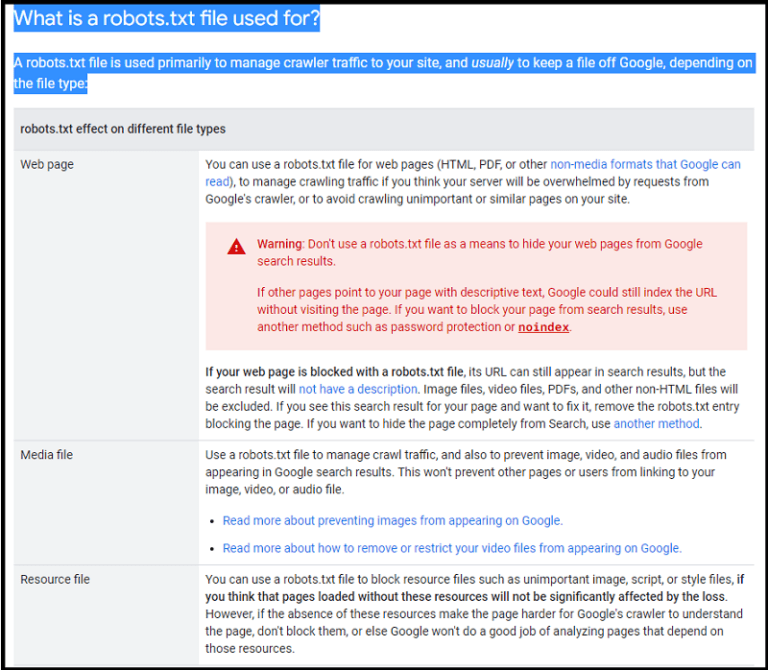
A robots.txt file is a crucial component of website design, acting as a guide for web crawlers, like those used by search engines. It’s a simple text file located in the root directory of a website, containing instructions for crawlers on which parts of the site they are allowed to access. This control is essential for maintaining site integrity and managing crawl frequency.This file essentially dictates which parts of your website are accessible to web crawlers, preventing them from indexing unwanted content or crawling resources you might prefer not to be publicly accessible.
It’s a fundamental aspect of search engine optimization and website maintenance.
Robots.txt File Purpose
Robots.txt files are used to control how search engine bots and other web crawlers interact with a website. By providing specific instructions, site owners can prevent crawlers from accessing certain files or directories, or restrict the frequency with which they crawl. This is particularly useful for protecting sensitive data, maintaining website performance, or managing the crawl budget for larger sites.
Ways Robots.txt Can Manage Web Crawlers
- Disallowing access to specific directories: This is a common use case, where site owners may wish to prevent crawlers from indexing sensitive data, such as user accounts or internal documents. A specific line in the robots.txt file can instruct crawlers to ignore a specific directory, such as /admin or /protected_data.
- Restricting the frequency of crawling: The robots.txt file allows for the specification of how often a crawler should visit a particular page or directory. This is useful for managing server load and ensuring that resources are not over-utilized. For example, a site owner might instruct crawlers to only crawl a certain page once every 24 hours.
- Providing sitemaps: A sitemap is a file that lists all the pages on a website, which helps search engines discover and index the pages effectively. The robots.txt file can direct crawlers to the sitemap to ensure that all relevant pages are included in the index. This is essential for large sites with many pages.
Robots.txt File Structure and Format
The robots.txt file uses a simple text-based format, with directives and corresponding paths. The file is structured with lines that begin with directives (e.g., User-agent, Disallow, Allow), followed by a path. The path indicates the specific part of the website to which the directive applies. A critical aspect of the structure is the use of wildcard characters (*) and the order of directives.
The structure follows a specific syntax. Each line typically consists of a directive, followed by a path or other parameters. The format is straightforward and easy to understand.
Example Robots.txt File
This example demonstrates a basic robots.txt file for a website with a few key directories:“`User-agent:Disallow: /adminDisallow: /protected_dataAllow: /Allow: /imagesAllow: /blog/*“`This example file instructs all web crawlers (* User-agent:) to not access the /admin and /protected_data directories. However, all other parts of the site, including the root directory (/), images, and blog posts ( /blog/* ) are allowed. The use of the wildcard (*) in the “Allow” directive for blog posts allows access to all subdirectories under the /blog directory.
Robots.txt for Marketing
Robots.txt, a simple text file, often overlooked, plays a surprisingly crucial role in a website’s marketing strategy. It acts as a communication channel, instructing search engine crawlers and other bots about which parts of your website they can or cannot access. Understanding how to leverage Robots.txt strategically can significantly impact your search engine optimization () efforts.This file is a vital part of website management, allowing you to control how search engine bots crawl and index your content.
Strategic implementation of robots.txt directives can enhance performance and prevent unwanted crawling.
Strategic Use of Robots.txt for Marketing
Robots.txt isn’t just about blocking crawlers; it’s a tool to guide them, ensuring that they prioritize valuable content. You can steer crawlers away from less important sections of your website, directing their focus toward the pages you want them to index and rank highly.
Relationship Between Robots.txt and
Robots.txt and are intrinsically linked. A well-structured robots.txt file can help search engines understand your website’s architecture, prioritizing the pages that contribute most to your site’s value and authority. This improved understanding can lead to better rankings in search results. Conversely, a poorly implemented robots.txt file can hinder search engine indexing, leading to a decline in visibility.
Impact of Directives on Search Engine Visibility
Specific directives within robots.txt have a direct impact on search engine visibility. The `Disallow` directive prevents search engine crawlers from accessing specific directories or files. The `Allow` directive, used in conjunction with `Disallow`, specifies which resources crawlers are permitted to access. For instance, blocking access to dynamically generated pages that don’t offer substantial value can help optimize the crawl budget of search engine crawlers.
This optimized crawl budget can lead to better indexing of important content.
Common Errors in Robots.txt Usage
Marketers often make mistakes in robots.txt implementation. One common error is blocking access to essential pages or directories that should be indexed. Another is using overly broad disallow rules that unintentionally block valuable content. For example, blocking the entire `/images/` directory without specifying exceptions for optimized images used in the site can be detrimental. Similarly, omitting the `Allow` directive when necessary can also limit crawlers’ access to content.
Examples of Effective Robots.txt Implementation
A well-structured robots.txt file can significantly improve search engine visibility. Consider a scenario where a website has a large number of dynamically generated pages. A robots.txt file can instruct search engines to focus on static pages with valuable content, leading to a higher ranking for those pages. Similarly, for e-commerce websites, strategically blocking access to generated product listings that are not ready for public view can help maintain an optimized crawl budget.
Blocking access to pages that are under construction or are intended for specific users, such as logged-in users, is another effective approach.
Directives and Rules
The Robots.txt file acts as a crucial communication channel between your website and search engine crawlers. It dictates which parts of your site these bots are allowed to access. Properly configured, it can significantly impact how search engines index and display your content. Incorrect configuration, however, can hinder your website’s visibility and overall performance.Understanding the directives within Robots.txt allows you to precisely control the crawling process, ensuring that your valuable content is indexed while protecting sensitive or less relevant information.
Robots.txt marketing is all about controlling what search engine crawlers see on your site. It’s like a digital gatekeeper, telling bots which pages to ignore. This is crucial for optimizing your website’s performance and preventing unwanted indexing. Similarly, API application programming interface marketing, as explained in api application programming interface marketing explained , involves strategically using APIs to boost your business.
Ultimately, though, proper robots.txt implementation is essential for managing the visibility of your content and keeping your site healthy for search engine optimization.
This meticulous control helps to maintain optimal website performance and improve .
User-agent Directives
This directive specifies the search engine bots that the rules in the file apply to. For instance, you can tailor instructions specifically for Googlebot, Bingbot, or other major search engine crawlers. This allows for different crawling behaviors depending on the bot.
- Defining a specific user-agent like ‘Googlebot’ ensures that the directives are only applied to Google’s crawler, while leaving rules for other bots untouched.
- Using a wildcard ‘*’ as the user-agent applies the directives to all bots, but this approach is less precise and might not be optimal for specialized instructions.
Allow and Disallow Directives
These directives specify the sections of your website that should or should not be crawled. The “Allow” directive grants access, while “Disallow” restricts access.
- The “Disallow” directive instructs crawlers to not crawl specific directories or files. For example, “Disallow: /admin/” prevents crawlers from accessing your administrative panel. This is vital for protecting sensitive areas of your site from indexing.
- The “Allow” directive is used to grant access to specific directories or files that you want indexed. Combining “Disallow” and “Allow” directives allows for precise control over which parts of your site are crawled.
Example Usage and Impact
Let’s illustrate the impact of these directives with a practical example. Imagine an e-commerce website with product listings in a directory named ‘/products/’.
- To prevent crawlers from indexing the entire product directory, you would use a “Disallow” directive for ‘/products/’.
- However, to index individual product pages, you would use “Allow” directives for specific URLs, such as “/products/category/dress/” or individual product pages like “/products/dress-123”.
| Directive | Effect on |
|---|---|
| Specific User-agent (e.g., Googlebot) with Allow for a product category | Improves by allowing Google to crawl and index specific product categories, thereby improving visibility for those products in search results. |
| Disallow for sensitive areas | Protects sensitive information and maintains website security by preventing indexing of areas like the administrative dashboard. |
| Disallow for dynamically generated pages | Avoids indexing pages that are not valuable for search results, conserving crawl budget for more important content. |
By strategically using “Allow” and “Disallow” directives, you can manage the indexing process, improving performance and ensuring your most relevant content is visible to search engines.
Implementation and Best Practices
Now that you understand the fundamental principles of robots.txt and its importance in marketing, let’s dive into the practical aspects of implementing it effectively on your website. Proper implementation is crucial for controlling web crawlers’ access to your site and ensuring your efforts are not hindered.
A well-structured robots.txt file acts as a roadmap for search engine crawlers, guiding them through your website’s architecture and indicating which parts should be prioritized or excluded. This is essential for optimizing crawl budget and preventing unwanted indexing of specific pages.
Creating a Robots.txt File
Creating a robots.txt file is a straightforward process. It’s a simple text file placed in the root directory of your website (e.g., www.example.com/robots.txt). The file uses a specific syntax to communicate with search engine crawlers.
Adding and Updating Robots.txt Files
Adding or updating your robots.txt file involves editing the text file directly. A text editor is sufficient for this task. Be sure to save the file in plain text format to avoid encoding issues. Updating is simply a matter of modifying the existing directives or adding new ones. Carefully review your changes before uploading to avoid any errors.
- Open the robots.txt file in a text editor.
- Add or modify the directives as needed. For example, to disallow crawling of a specific directory, add a line like:
Disallow: /private/ - Save the changes to the robots.txt file.
- Upload the updated file to the root directory of your website.
- Verify the changes by checking the file’s content and ensuring that the correct directives are implemented.
Best Practices for Robots.txt Implementation
Implementing robots.txt effectively involves more than just creating the file. Here are best practices to consider:
- Prioritize clarity and conciseness. Use clear and concise language in your directives. Avoid overly complex rules that may confuse crawlers. Focus on specific directories or files, avoiding broad disallows that could hinder the indexing of important content.
- Maintain accurate and up-to-date directives. As your website evolves, you should regularly review and update your robots.txt file. New pages, directories, and changes to your site structure will necessitate modifications to the file to ensure accurate control over crawlers.
- Thoroughly test and validate the robots.txt file. Always test your robots.txt file to ensure it functions correctly. Tools exist to check the syntax and ensure the directives are implemented as expected. This validation step prevents issues later on.
Common Robots.txt Directives and Their Effects
Different directives in the robots.txt file convey various instructions to search engine crawlers. The following table illustrates the most common directives and their impacts on crawling behavior.
| Directive | Effect |
|---|---|
| User-agent: – | Applies to all web crawlers. |
| Disallow: /private/ | Prevents crawling of the /private/ directory and its subdirectories. |
| Allow: /images/ | Allows crawling of the /images/ directory and its subdirectories. |
| Sitemap: https://www.example.com/sitemap.xml | Provides a link to your sitemap, helping crawlers understand your website structure. |
Advanced Techniques
Robots.txt, while seemingly simple, offers powerful tools for optimizing website performance, security, and traffic management. Beyond basic blocking, advanced techniques unlock the full potential of this file, allowing website owners to fine-tune how search engines and other crawlers interact with their site. Understanding these strategies can significantly impact search engine visibility and overall website health.
Protecting Sensitive Information
Robots.txt can act as a crucial first line of defense against unauthorized access to sensitive data. By explicitly forbidding crawlers from accessing specific directories or files, website owners can safeguard confidential information. This includes user data, internal documents, and other proprietary material. This preventative measure is particularly useful for e-commerce sites handling financial transactions or companies dealing with confidential client data.
Understanding robots.txt is crucial for SEO, essentially telling search engines which parts of your website to crawl. Knowing how to optimize it can significantly impact your online presence. But, for more targeted reach, you might also consider Facebook Ads Manager marketing. This powerful tool allows for highly customized campaigns, enabling you to reach specific audiences, and optimize your budget for maximum return.
Learning about Facebook Ads Manager, as detailed in this excellent guide facebook ads manager marketing explained , can really boost your marketing efforts. Ultimately, while robots.txt ensures search engines respect your site’s structure, effective marketing campaigns like those using Facebook Ads can drive traffic and conversions.
Proper configuration ensures that sensitive information isn’t indexed or accessible to unauthorized entities.
Managing Website Traffic and Resources
The robots.txt file isn’t just about blocking access; it can also be used to manage the volume and types of requests a website receives. This allows for more efficient use of server resources and potentially reduces website load times. By instructing crawlers to prioritize certain sections or to avoid certain pages, site owners can influence the focus of crawling, thereby managing the amount of data processed by search engines.
For instance, a website with a large amount of media content can instruct crawlers to prioritize indexing of text content over images or videos. This strategy can be critical for websites with substantial resources or content.
Utilizing Robots.txt for Sitemaps and Related Tools
Robots.txt can be used in conjunction with other website tools, like sitemaps, to enhance search engine optimization. A sitemap provides a comprehensive list of all pages on a website. Robots.txt can then direct crawlers to prioritize or avoid certain sections of the sitemap, allowing for a more focused crawling strategy. For instance, if a website has a new section or a significant update, a robots.txt directive can be used to temporarily prevent search engine indexing of that section, while a sitemap still accurately reflects the website structure.
This ensures the search engines are aware of the new content without immediately processing it, allowing for a smoother and more controlled indexing process.
Advanced Directives and Syntax
Robots.txt offers advanced directives beyond the basic “Allow” and “Disallow” instructions. These allow for more nuanced control over crawling behavior. For instance, the “Crawl-delay” directive tells crawlers how long to wait between requests, preventing overwhelming the server. Understanding these directives can lead to a significant improvement in website performance.
Example of Crawl-Delay Usage
A website experiencing high traffic might use a crawl-delay directive to reduce the load on the server. The crawl-delay directive would specify a wait time, in seconds, before the next request. This would help in spreading out the workload and preventing the server from being overloaded.
Example:“`User-agent:Crawl-delay: 2Disallow: /private/“`This example instructs all crawlers (*) to wait 2 seconds between requests, while still preventing access to the /private/ directory.
Troubleshooting and Common Issues
Robots.txt, while a powerful tool for controlling web crawlers, can sometimes lead to unexpected consequences if not implemented correctly. Understanding common pitfalls and troubleshooting techniques is crucial for maintaining optimal website performance and visibility. This section delves into typical problems, providing actionable solutions and analysis methods.
Common Robots.txt Implementation Errors
Incorrectly configured robots.txt directives can block search engine crawlers from essential pages, impacting website indexing and visibility. Common mistakes include inadvertently blocking important pages, misusing wildcards, and using incorrect syntax. Errors in file permissions or server configuration can also prevent the robots.txt file from being accessible.
- Blocking essential pages: Carelessly blocking critical pages, like product listings or blog posts, is a frequent error. Double-checking the inclusion of all necessary pages in the allow section is paramount. Example: If you want Googlebot to index your product pages, ensure the corresponding URLs are explicitly allowed.
- Incorrect use of wildcards: Using wildcards incorrectly can lead to unintended consequences. For example, if a site uses a wildcard like
-products*, it could inadvertently block all pages that contain the word “products,” potentially excluding relevant content. Careful planning and testing are crucial. - Syntax errors: Incorrect syntax within the robots.txt file can prevent crawlers from properly interpreting directives. These errors can be easily overlooked but significantly affect the crawl process. Checking for proper formatting and capitalization is essential.
- File permissions issues: If the robots.txt file’s permissions are not set correctly, search engine crawlers might not be able to access it. Ensure the file has the correct permissions to allow public access.
Troubleshooting Robots.txt Issues
Diagnosing robots.txt problems requires a systematic approach. Begin by checking the file’s syntax for any errors. If the file is accessible, verify that the directives are correctly written and include the appropriate permissions.
- Verify file accessibility: Attempt to access the robots.txt file directly from a web browser. If you cannot view it, there may be server-side issues preventing access. This is a critical initial step.
- Inspect robots.txt syntax: Use a text editor to carefully review the robots.txt file for any typos or inconsistencies. Validating the file against a robots.txt validator can identify potential syntax errors.
- Test crawl behavior: Employ tools like Google Search Console or other crawling tools to examine how search engine crawlers are interacting with your site. Look for specific errors or blocked URLs. This helps pinpoint the cause of the problem.
- Analyze server logs: Review server logs for any error messages related to the robots.txt file. This can provide insights into the specific reason for the problem.
Analyzing the Impact of Robots.txt Changes
Monitoring website performance after making robots.txt changes is essential. Tracking key metrics, like indexed pages and crawl rate, provides insights into the effectiveness of the modifications.
- Tracking indexed pages: Use Google Search Console to monitor the number of pages indexed after making changes to the robots.txt file. A decrease in indexed pages could indicate that crucial pages are blocked.
- Checking crawl rate: Monitor the crawl rate to ensure that search engine crawlers are not being significantly affected by the new robots.txt file. If the crawl rate decreases drastically, it could indicate an issue with the implementation.
- Reviewing sitemaps: Update sitemaps after implementing robots.txt changes. This helps search engines discover the correct pages and update their indexing accordingly.
Common Errors and Mistakes
Careless implementation of robots.txt can significantly impact a website’s search engine visibility. Some common mistakes include blocking important directories, using incorrect wildcards, and failing to test the file thoroughly before deploying it.
- Blocking critical directories: Blocking entire directories or subfolders can unintentionally prevent search engine crawlers from accessing essential content. This can negatively affect site indexing and overall visibility.
- Incorrect wildcard usage: Using wildcards without careful consideration can lead to unintentional blocking of relevant pages. Thorough testing and validation are critical.
- Failure to test thoroughly: Before deploying any changes to the robots.txt file, rigorous testing is vital. Testing with various search engine crawlers helps identify any unexpected or unintended consequences.
Robots.txt and Mobile
Robots.txt, while primarily focused on web crawlers, plays a significant role in mobile and website indexing. Understanding how mobile user-agents interact with this file is crucial for optimizing your site’s visibility to mobile search engines. Mobile-specific directives allow you to control how different search engine crawlers access various parts of your site, ensuring optimal indexing and presentation in search results.Mobile devices are now the dominant way people access websites.
This shift in user behavior necessitates a nuanced approach to robots.txt management, focusing on delivering the best possible mobile experience while ensuring search engines can properly index your content. Optimizing for mobile-first indexing means that the mobile version of your website is prioritized, and robots.txt plays a key part in this process.
Understanding robots.txt is crucial for SEO, but sometimes the best marketing strategies are right in front of you. For fitness equipment makers, focusing on affordable social media help, like the services offered at affordable social media help for fitness equipment makers , can significantly boost brand visibility. After all, a well-optimized robots.txt file ensures search engines crawl and index your site effectively, which is a key component of any successful online marketing plan.
Mobile-Specific Robots.txt Directives
Mobile search engines, like those from Google and Bing, often use specific user-agent strings. By recognizing these strings, you can tailor your robots.txt directives to specifically address their requests. This allows for different crawling behavior for mobile versus desktop users.
Impact on Search Engine Rankings
Properly configured robots.txt for mobile can have a positive impact on search engine rankings. By allowing search engine crawlers to access the most relevant mobile content, you ensure they can create accurate and comprehensive indexes of your site. This, in turn, leads to higher rankings for mobile search results. A well-structured robots.txt file that prioritizes mobile content can help your website achieve higher positions in search engine results pages (SERPs).
Mobile-Friendly Robots.txt Implementations
A well-implemented robots.txt for mobile should allow for optimized indexing. A good example would be allowing mobile crawlers to access all pages but disallowing access to specific directories for non-essential content. This keeps the mobile version of your website clean and focused on what matters most to mobile users.
- Allowing mobile crawlers access to critical content, such as product pages, category pages, and blog posts, is essential for mobile search optimization.
- Disallowing access to less critical or dynamic content, like backend systems or administrative pages, helps maintain the focus on the mobile experience. This keeps the site’s mobile version clean and uncluttered.
- Using specific user-agent strings for mobile crawlers allows you to tailor the crawling behavior for the mobile experience, preventing indexing issues or unnecessary crawl load.
Managing Mobile User-Agent Requests
Understanding how to manage mobile user-agent requests within robots.txt is crucial for mobile . This involves identifying the specific user-agent strings associated with different mobile search engine crawlers. This allows you to control the level of access each user-agent has to different sections of your website, ensuring that critical content is properly indexed.
| User-Agent | Action |
|---|---|
| Googlebot-Mobile | Allow access to all content |
| Bingbot-Mobile | Allow access to all content |
| Other Mobile Crawlers | Allow access to all essential content, block non-critical content |
Using these examples and understanding the different user-agent strings associated with mobile search engine crawlers will improve your robots.txt implementation and ensure mobile search engines can crawl your site effectively.
Case Studies

Robots.txt, often overlooked, plays a crucial role in a website’s performance and marketing success. Understanding how various companies leverage this simple file to manage web crawlers can significantly impact , user experience, and overall site health. Successful implementations of Robots.txt demonstrate its power in controlling crawl budgets and optimizing resource allocation for both search engines and the website itself.By analyzing real-world examples, we can gain valuable insights into how different organizations tailor their Robots.txt directives to meet their unique marketing objectives.
This section delves into several case studies, highlighting the strategic use of Robots.txt to enhance website performance and improve the user experience.
Successful Implementations of Robots.txt, Robots txt marketing explained
Robots.txt isn’t just a technicality; it’s a strategic tool for managing website traffic and resource allocation. Several businesses have used it effectively to achieve specific marketing goals.
| Company | Marketing Objective | Robots.txt Strategy | Impact |
|---|---|---|---|
| E-commerce Retailer A | Improve site speed and reduce server load. | Blocked crawling of unnecessary pages, like those with low value or frequently updated product listings. | Significant reduction in server requests, resulting in improved site speed. Positive impact on customer experience and search engine rankings. |
| Blog Platform B | Prioritize high-value content and protect against spam. | Allowed crawling of high-quality blog posts and resources, while blocking spam submissions. | Improved search engine rankings for valuable content. Reduced crawl load on the site, preventing the resources from being drained by spam or low-quality content. |
| News Publication C | Maintain a high-quality user experience and manage server resources. | Optimized crawling for important sections like the homepage and key news articles. Blocked crawling of less important sections like old archives, preventing excessive server demands. | Improved page load times, resulting in better user engagement. Enhanced rankings by directing search engine crawlers to valuable content. |
Optimizing Website Performance with Robots.txt
Robots.txt can be a valuable tool for enhancing website performance. By strategically blocking or allowing access to specific directories or files, companies can optimize resource allocation, resulting in improved site speed and user experience.
- Reduced server load: Blocking access to unnecessary pages or resources reduces the number of requests a server must handle. This directly translates to reduced server load, enabling the website to perform more efficiently.
- Improved site speed: By preventing the crawling of unnecessary pages, websites can improve their loading times. This is particularly important for e-commerce sites, as faster loading times can lead to improved conversion rates and customer satisfaction.
- Enhanced : By directing crawlers to high-value content, companies can improve their rankings. This prioritization ensures that the most relevant pages are indexed and displayed prominently in search results.
Robots.txt and Marketing Objectives
Different businesses employ Robots.txt for various marketing objectives. The effectiveness of Robots.txt is highly dependent on how the directives are implemented and tailored to specific needs.
- E-commerce sites: Prioritize the crawling of product pages and categories while blocking crawling of unnecessary or dynamically generated content, ensuring the most relevant information is indexed.
- News publications: Focus on important articles and news updates while restricting crawling of archives or less relevant content, optimizing the indexing of current news items.
- Blogs: Prioritize high-quality content while blocking the crawling of spam submissions or low-value content, resulting in improved search engine rankings.
Future Trends
The landscape of website optimization is constantly evolving, and robots.txt, while seemingly a static file, is not immune to these changes. Predicting the future of robots.txt requires understanding emerging technologies and how they’ll impact search engine crawlers, as well as the evolving needs of website owners. The key is anticipating how search engine algorithms and user behavior will influence the best strategies for managing crawler access.The future of robots.txt will likely involve a greater emphasis on dynamic control and more sophisticated rules based on the specific needs of different parts of a website.
Instead of a one-size-fits-all approach, websites will likely employ more nuanced strategies to manage crawl budgets and prioritize content, leading to a more precise control over the indexing process.
Emerging Impact of New Technologies
Modern web technologies are altering how search engines operate. The rise of JavaScript-heavy websites and server-side rendering, for instance, makes it more critical to control which resources crawlers access. A proper robots.txt implementation can prevent crawlers from hitting performance bottlenecks by focusing on the critical components of the site. Additionally, structured data markup, like schema.org, plays a role in how search engines understand the content.
This necessitates robots.txt to ensure that crawlers correctly process and index this valuable data, and in turn, deliver a more meaningful search experience to users.
Impact on Website Marketing
Robots.txt is no longer a purely technical tool; its impact on marketing strategy is becoming increasingly important. As search engines become more sophisticated in their understanding of user intent, robots.txt will play a more significant role in influencing the content that appears in search results. Websites that strategically manage their crawl budget can better optimize for specific s or topics, leading to improved visibility and organic traffic.
A well-managed robots.txt can enhance the user experience by preventing slow-loading pages and wasted crawl resources.
Potential Challenges
The complexity of modern websites and the constant evolution of search engine algorithms will present challenges for managing robots.txt. Ensuring that a robots.txt file accurately reflects the dynamic structure of a website can become increasingly difficult. Furthermore, the need for fine-grained control might lead to over-optimization, potentially causing confusion for search engine crawlers. Careful testing and monitoring will be essential to ensure the effectiveness of robots.txt strategies.
Future of Robots.txt Usage
The future will see a shift from simply blocking crawlers to actively guiding them. Websites will likely use robots.txt to provide search engines with detailed instructions on the structure and priority of content, potentially including instructions for handling JavaScript-heavy pages or dynamic content. Furthermore, the rise of mobile-first indexing will necessitate adjustments in robots.txt to ensure that mobile content is correctly indexed and prioritized.
Concluding Remarks: Robots Txt Marketing Explained
In conclusion, mastering robots.txt is a significant step towards optimizing your website for search engines. By strategically utilizing its directives, you can effectively control how search engine bots interact with your site, ultimately enhancing your and driving more organic traffic. Implementing best practices and understanding potential issues are key to success. This comprehensive guide provided a roadmap to navigate the world of robots.txt marketing and empower your website’s online presence.